
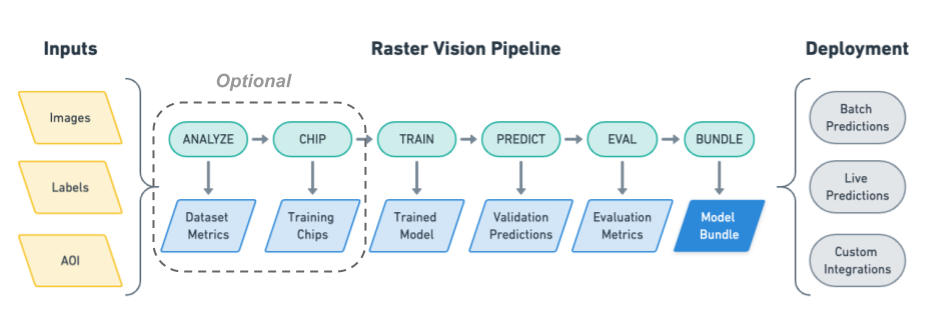
Raster Vision 0.13 is now live. This release presents a major jump in Raster Vision’s power and flexibility. The newly added features, enabled by the major refactoring in the last Raster Vision release, allow for finer control of the model training as well as greater flexibility in ingesting data. We highlight here some of the major new features. For a full list of changes, please see the official changelog.
Highlights
This release allows you to:
Skip the Chip stage: Read directly from raster sources during training (#1046)
You are now no longer required to go through a chip stage to produce an intermediate training dataset. Raster Vision can now sample chips from the raster sources on-the-fly during training. All the examples now use this as the default. Check them out to see how to use this feature.
Skip the Analyze stage (#972)
It is no longer necessary to go through an analyze stage to be able to convert non-uint8 rasters to uint8 chips. Chips can now be stored as numpy arrays, and will be normalized to float during training/prediction based on their specific data type. See spacenet_vegas.py for example usage.
Currently only supported for Semantic Segmentation.
analyze and chip stages and jump directly to training in certain cases.Import and use arbitrary models and loss functions (#985, #992)
You are now no longer restricted to using the built-in models and loss functions. It is now possible to import models and loss functions from an external source (such as a GitHub repo, a URI, or a zip file). As long as they interface correctly with Raster Vision’s learner code, you are good to go. This is made possible via PyTorch’s hub module.
This makes it trivial to switch models/losses and try out a bunch of them. This also means that you can now take advantage of the latest available models. Or make model/loss customizations specific to your task. All with minimal changes.
Train on multiband images (even with Transfer Learning) (#972, #1026)
You can now train on imagery with more (or less!) than 3 channels. Raster Vision automatically modifies the first layer of the model such that it is able to accept whatever number of channels you are using. When using pre-trained models, the pre-learned weights are retained.
These model modifications cannot be performed automatically when using an external model, But as long as the external model supports multiband inputs, it will work correctly with Raster Vision.
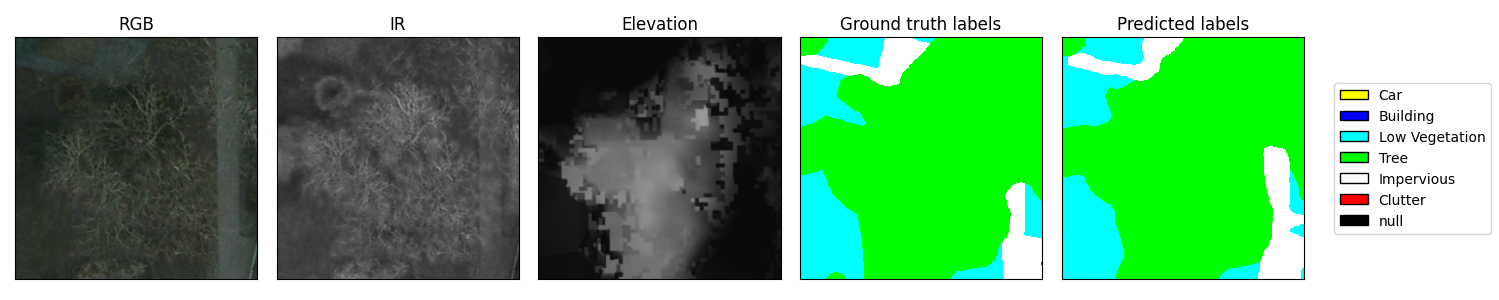
Currently only supported for Semantic Segmentation.
Use arbitrary transforms for data augmentation (#1001)
You now have complete freedom in your choice of the data augmentations you want to use. Raster Vision can now work with whatever Albumentations transform you give it. You may specify three kinds of transforms:
- A
base_transformthat is used by all datasets: in training, validation, and prediction. - An
aug_transformfor data augmentation that is only applied during training. - A
plot_transform(viaPlotOptions) to ensure that sample images are plotted correctly. For example, you can useplot_transformto rescale a normalized image to 0-1.



ToGray, CutOut, ImageCompression, and GridDistortion Albumentations transforms.Do streaming reads from Rasterio sources without downloading them (#1020)
It is now possible to stream chips from a remote RasterioSource without first downloading the entire file. To enable, set allow_streaming=True in the RasterioSourceConfig.
Future Work
In the short term, we would like to extend the new functionality so that it is available for all 3 computer vision tasks that Raster Vision supports. Additionally, we would like to allow users more control over the optimizer and scheduler. Support for multi-GPU training is also on the todo-list. In the longer term, we would like to add support, if feasible, for semi-supervised learning approaches.