
The author of this image is Cosmia Nebula, and you can view licensing information here.
Knowing who one’s representatives are and how to contact them is essential for a well-functioning Republic. Azavea’s Cicero database helps to facilitate that knowledge by collecting essential information about politicians from their websites (name, contact, information, constituency, and so on) into a convenient and centralized form. However, this information has traditionally been collected by humans, which can be excessively exhausting and time-consuming.
In this blog post, we describe our work toward addressing that problem by automating the task using state-of-the-art Natural Language Processing. The form of the Cicero Database required us to do extensive work to create datasets suitable for NLP training. Namely, we have conducted several steps of data processing to coerce the current Cicero Database into several usable BIO-labeled NER datasets. We consistently put effort into improving the quality of these datasets. We trained the four language models in total to extract different categories of information. Both the numerical evaluation and concrete predictions of models indicate promising results. We open-source our code at https://github.com/azavea/cicero-nlp.
What is the Cicero Database?
The Cicero database is a comprehensive, highly-accurate database of elected officials and legislative districts in 9 countries worldwide. It is made from public information that can be found on official government websites, and the information is organized into different categories. Those categories include names, phone numbers, fax numbers, and other contact information plus social media identifiers. The source URLs from official government websites are also incorporated into the dataset. A sample of the Cicero Dataset is shown below.
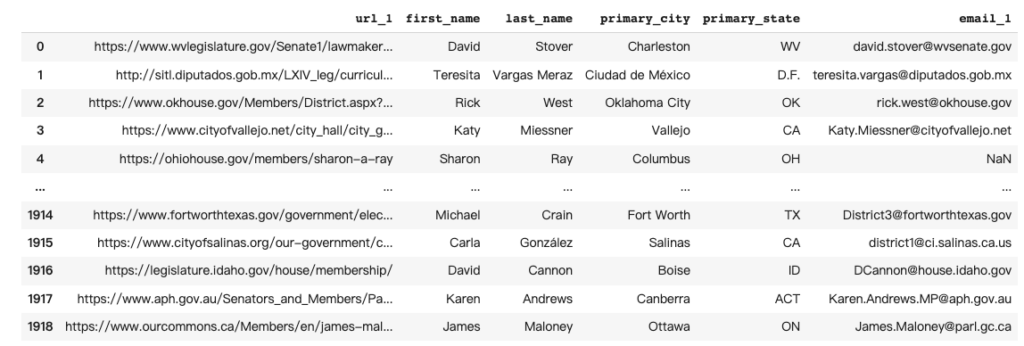
Historically, this large dataset of over 57,000 historical and current officials was collected and managed via extensive human annotation and data entry efforts. Specifically, human annotators will be provided with a list of information categories that need to be collected for the Cicero Database. They will then go to the official government website to find and enter data that fits into any of those categories into the database. This process of human annotation can be quite slow and expensive.
Why Named Entity Recognition(NER) and How to use Cicero Database for a NER task?
The collecting information process of human annotators is actually extracting spans of interest from contexts, and these spans are typically in the form of nouns or noun phrases. This process shares a significant amount of similarity with the Named Entity Recognition task in the field of Natural Language Processing.
Natural Language Processing (NLP) is the interdisciplinary field of Computer Science and Linguistics and it is a subfield of artificial intelligence. NLP involves various useful and interesting applications, like Sentiment Analysis and Named-Entity Recognition.
Named-Entity Recognition (NER), is to identify named entities like persons, locations, organizations, and dates in the text. NER is widely used in information retrieval, text understanding, question answering, and more (Yadav & Bethard, 2019; Li et al., 2022). As seen in the example below, the NER task involves two main steps: identifying named entities and then classifying them into the appropriate categories.

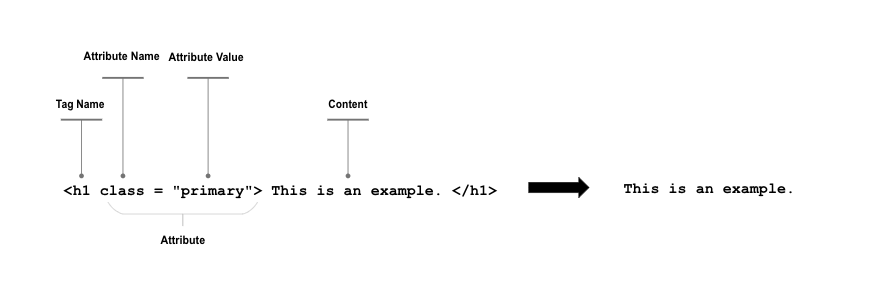
Although the Human annotators’ process to make Cicero Database is similar to the NER task, and the Cicero Database is well-organized, it cannot be used as a NER dataset to train language models. A typical NER dataset is sequence-labeled, with each word in the input being assigned a specific label. The standard approach to sequence labeling is Beginning-Inside-Outside (BIO) tagging (Ramshaw & Marcus, 1995), which allows the labels to encode both the boundaries and the named entity type (Jurafsky & Martin, 2022).
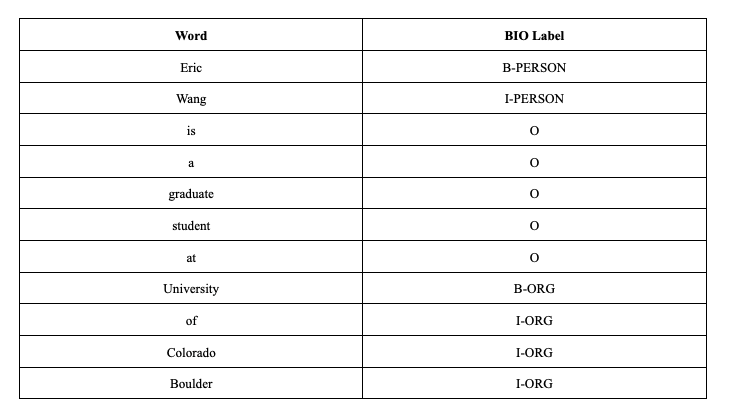
In the above example, each word in the sentence is labeled with both boundary information and the named entity type. Words that begin a span of interest are marked with a “B” tag, words that sit inside a span of interest are marked with an “I” tag, and words outside of any span of interest are marked with an “O” tag. The “B” and “I” tags have different entity types, but the “O” tag is not associated with any entity type. if a BIO-tagged NER dataset only contains two entity types, such as PERSON and ORG, there will be a total of five different labels in the dataset. The BIO tagging allows the dataset to represent the entities accurately and precisely with their context surrounded.
In comparison to a BIO-tagged NER dataset, the Cicero Database only contains a list of spans without the context of these entities and without proper labeling. This leads to the fact that the data in the Cicero Database cannot be used to train NER models directly.
We perform several data processing steps to coerce the Cicero Database into a usable NER dataset. This involves
- Scrape source web pages by using the URLs stored
- Clean web pages and convert them into pure texts
- BIO tags the span of interest in the pure texts
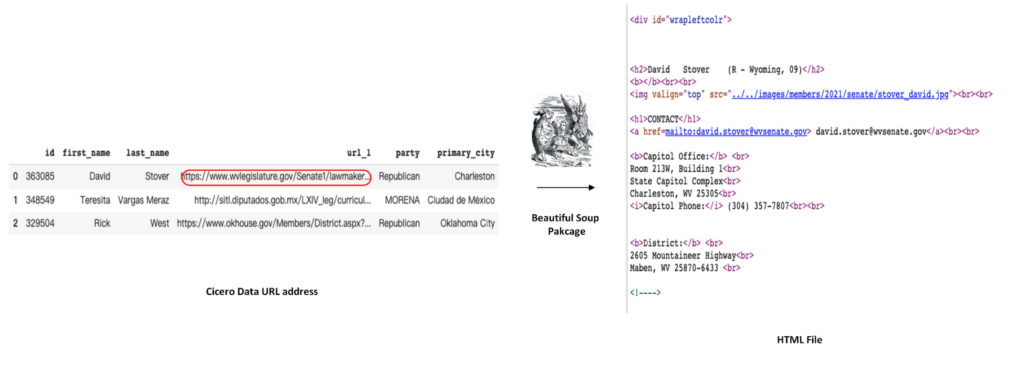
Scrape source web pages
For the first step, given the URL addresses stored in the Cicero database, we use the BeautifulSoup package to scrape the politicians’ web pages. The scraped web pages are stored in the format of HTML files.
Clean web pages and convert them into pure texts
The second step is to clean the HTML files, removing the HTML attributes, tags, and values of tags. Through this process, only the core content will be left and transferred into pure texts. Since one can assume that HTML elements (like tags) don’t contain any spans of interest for our downstream NER task, removing those unwanted elements helps to improve the performance of models and decrease the size of intermediate data and the final datasets.
BIO tagging
For the last step of data processing, we need to BIO tag the information that is stored in the Cicero Dataset in the pure texts retrieved from the second step. That is to say, we need to identify where in each pure text the data in the corresponding Cicero entry was sourced. We encountered many unexpected complexities during this process because the information in the Cicero Database is frequently different from the information in the pure texts. There are two major reasons:
- First, the information changes with time (so our pure texts now may not be the same as the “pure texts” as they would have existed at the time the data were entered into the Cicero Database).
- Second, the information may be differently formatted or differently expressed (e.g. the “pure text” might give the politician’s mailing address as being on “Happy Street”, but the Cicero Database might record that address as being on “Happy St”).
BIO tagging in reality: Problems and Solutions
During the BIO tagging process, we can label most categories of information stored in the Cicero Database smoothly, including names, cities, counties, parties, and salutations. The challenges we countered primarily related to phone, fax, state, address, and email information. We were able to overcome these challenges by using regular expressions, incorporating external information, and generating synthetic datasets.
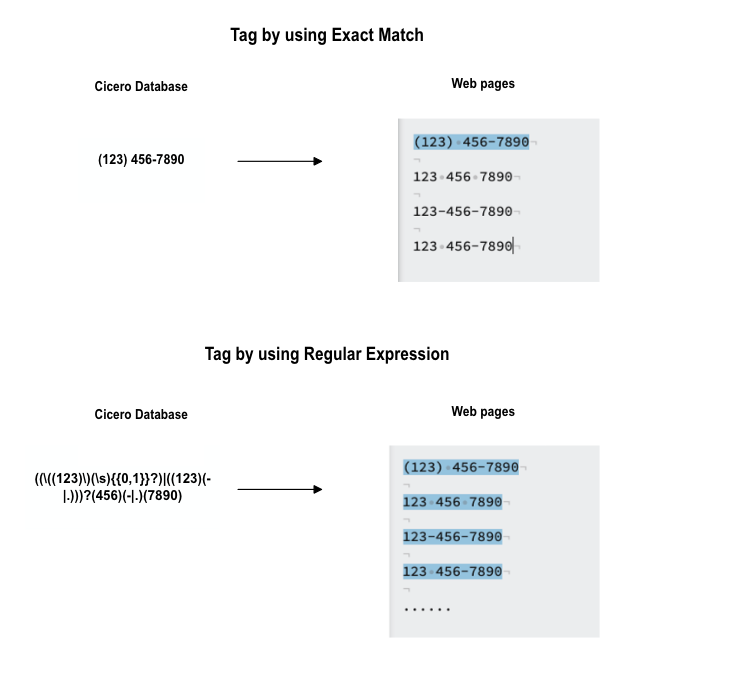
Phone and fax numbers
For US politicians, “(xxx) xxx-xxxx” and “xxx xxx xxxx” are the two most common formats in the Cicero Database. However, on the web pages, it is very likely that phone and fax numbers occur in different formats and cause problems in BIO tagging. Our experiments indicate that, if one only tags the phone and fax information by using the exact match, the trained model is biased and its predictions have high variance. To overcome this problem, we apply a regular expression during tagging, which can help us find and BIO-tag the corresponding phone and fax numbers more successfully.
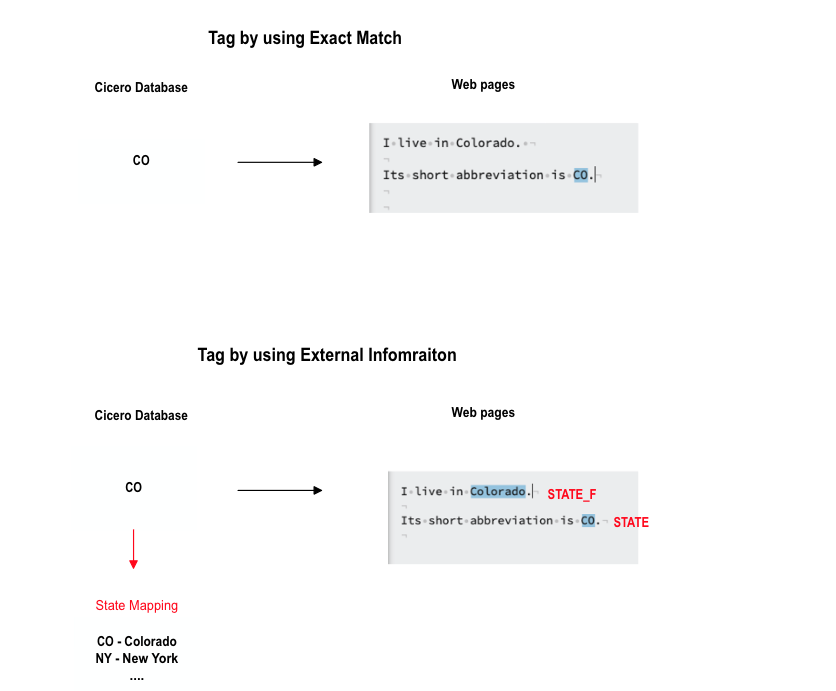
State names
The state information associated with each politician is stored in the Cicero database in the short abbreviation form (e.g. “FL” instead of “Florida”). In our experiments, we noticed that, in some cases, a politician’s state information is only expressed in its unabbreviated form. Unfortunately, models trained on the dataset without any special treatment of state information cannot extract the state information correctly under those conditions. To counter this problem, we introduce external information during BIO tagging on the state information: the BIO tagger will not only tag the short abbreviation but also the full names of states.
Moreover, in our experiments, we found that models’ performance tends not to be as promising when full state names and abbreviated state names are given the same category. We split these two formats of states into two different label types to solve this problem. One label is STATE and the other one is STATE_F (“F” for full).
Street addresses
Creating a training dataset with tagged address information was more complex than for the other data in which we were interested. Similar to phone numbers and state information, addresses can be expressed in multiple ways. For example, when occurring in an address, the word “boulevard“ can be expressed as “blvd” and the word “street” can be stated as “ST”. However, this intrinsic factor of the address information can not be solved by either of the methods that we applied for tagging phone/fax numbers nor the method we used for tagging state information.
For the regular expression method (the method used to tag phone and fax numbers), we attempted to use the first letters of the address information to match their occurrences. However, because address information is less structured than phone numbers are, it is challenging to match occurrences using only regular expressions. We found that attempting to do that will produce noisy results. For example, if we applied the first letter match pattern to find the address “City Hall, 1500 Warburton Avenue” in the context, the “CH” pattern would generate false positives like “City History”, “Commission Housing” and “Council History”, which will decrease the performance of our models.
The external information method we applied for solving the state name problem is also not suitable for the street address problem since the mapping between abbreviations and full names in the address field is often more complicated than the mapping for states, and such mapping relationships are very hard to collect. For instance, in the address, the word “Boulevard” can be expressed as “blvd.”, “ blvd”, “bd.”, “bd”, “bl”, etc.
We solve the street address problem by creating a synthetic dataset by inserting the address information into the essays. Since the address information is inserted by us, it is very easy to label them precisely in the context.

We chose to create the synthetic dataset since we notice the fact that the content on the webpages is not as coherent as the content in the normal texts, like stories, where semantic information is closely linked and tightly coupled to each other.
We chose essays in the Hewlett Automated Student Assessment Prize (ASAP) dataset (Jaison et al., 2012) as the source texts into which we inserted addresses because the essays in that dataset have already been stripped of sensitive and confidential information. Specifically, names and locations are blocked by special symbols in the essay dataset. For that reason, we can be confident that no other address will contaminate the synthetic dataset. That prevents unwanted noise from being introduced into the dataset.
We also applied several tricks during insertion to improve the quality of the dataset and improve the performance of the model. To better mimic the web pages in general, we also inserted other information from the Cicero Database into essays, including names, emails, and phone numbers. We noticed that the various bits of address information tend to occur together or close to one another on real web pages. To better reflect this situation, we inserted the address information altogether when creating the synthetic dataset. To increase the complexity of the synthetic dataset, we added named entities from CoNLL2003 (Sang & De Meulder, 2003) into essays as well. As the Location category is one of the main NER categories in CoNLL2003, some entities look very similar to real street addresses.
Email addresses
The challenges that we encountered in training a model to extract email information were unexpected. We thought that it would be easy for models to extract that information since email addresses are also very obvious and overt in the text. However, our experiments showed that the model performance on email address extraction was much lower than for other types of information.
Considering that politicians’ names and their email addresses are often strongly associated, we chose to create a synthetic dataset that simplifies the downstream task of the model. The input given to the model will only contain the full name of the politicians and all the possible email addresses found on the web pages. The model will take the full name of the politicians as a hint and use this hint to judge which email is the correct one.

Models and Training Models
As the result of our extensive effort on BIO tagging, we successfully generated two synthetic datasets for address and email respectively, and labeled the rest categories of information in their source context. We divided the remaining categories into two groups due to the large number of categories. In total, we have four datasets: two datasets of labeling information on the web pages text, one synthetic dataset for street addresses, and one synthetic dataset for email.
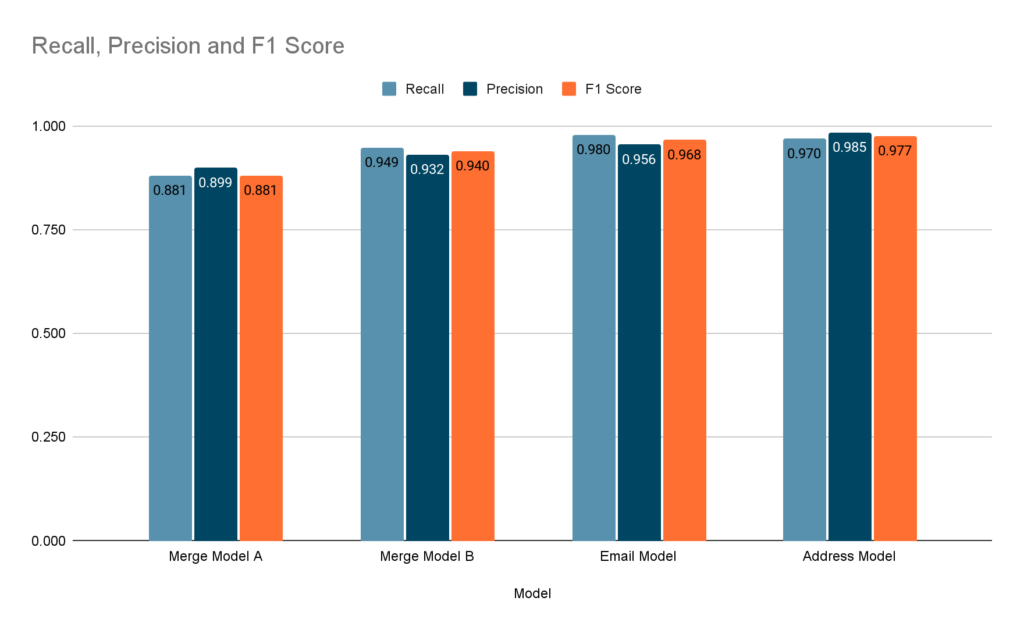
We trained four different models using the four datasets: Merge Model A, Merge Model B, Address Model, and Email Model. Merge Model A covers name, phone, and fax numbers. Merge Model B focuses on city, county, state, party, and salutation information. The Email Model is specifically trained to recognize email addresses, and the Address Model is trained to recognize street address information.
All four models apply the pre-train and fine-tune paradigm. The pre-train and fine-tune paradigm consists of two steps: pre-train and fine-tune, as its name says. The pre-train step trains a language model with a fixed architecture with very large datasets on self-supervised training objectives, without using human labeling. The fine-tune step adapts the language model trained from the pre-train step to some specific downstream tasks by adding additional parameters and layers on top of the language model (Liu et al., 2022). The pre-train and fine-tune paradigm has achieved remarkable success in a wide range of NLP tasks (Devlin et al., 2018; Lewis et al., 2018).
We used RoBERTa base as our language model. RoBERTa base is a transformer model (Vaswani et al., 2017) which contains 12 layers and 110 million parameters. It is pre-trained on five different English datasets totaling over 160 GB of text and it is pre-trained with the Masked Language Modeling (MLM) objective (Liu et al., 2019).
![Text "I am a student at [MASK] University"](https://www.azavea.com/wp-content/uploads/2023/01/image5.png)
We fine-tune the RoBERTa base on the four datasets using the spaCy library. To improve the reproducibility of models, we use the wandb library to visualize the training process and record the config files. We apply the Adam optimizer with an initial 5e-5 learning rate. The batch size is 128. The training process stops if there is no improvement in the last 1600 steps/batches.
We present the numerical evaluation results below, which show the model’s performance on the development sets.
To ensure that the model’s performance is consistent with the numerical evaluation, we also conducted a manual evaluation of the model. We present the model’s predictions on several specific cases below.




Future Work
Currently, we are in the very initial phase of this project and there are several possible directions for further exploration.
HTML-structure-aware Models
Currently we apply the RoBERTa as the language model, which does not take HTML structural information into account. Instead, we remove the HTML elements like tags, attributes, and values of attributes during data processing. However, the HTML structure contains important information and might be helpful to improve a model’s performance. For example, on a politician’s web page, their contact information like address, phone number, and fax numbers might occur with the same HTML tag. Moreover, dominant information, like politicians’ names, might occur in the heading tags on the web pages.
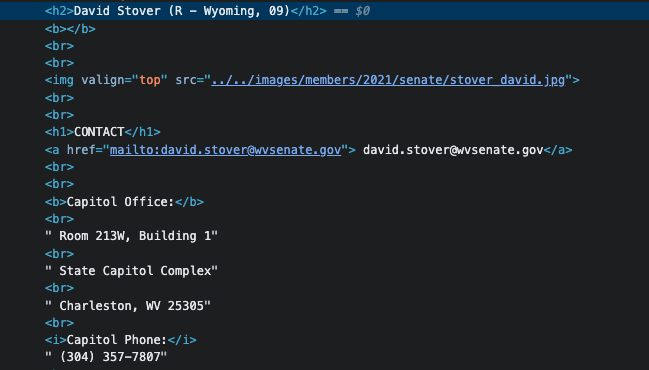
Models that can encode and leverage HTML structures, along with pure text, have brought significant performance improvements on a variety of web understanding tasks (Deng et al., 2022; Wang et al., 2022). Reimplementing and fine-tuning those models with preprocessed Cicero data might also bring us more robust and accurate models.
Non-US training
At this moment, we mainly focus on US politicians and the English language. The phone, fax, address and state information on the non-US politicians’ web pages will be largely different from current cases, let alone the web pages in other languages. Given this intrinsic difference, our models might have poor performance on those non-US data points. In the future, experiments that combine non-US datasets and current datasets could potentially increase the generalization ability of models.
Acknowledgement
The author would like to express gratitude to all the reviewers for their valuable feedback. The author would like to extend a special thanks to his mentor, James McClain, for his consistent and extensive support throughout the project.
References
Jacob Devlin, Ming-Wei Chang, Kenton Lee, & Kristina Toutanova. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. ArXiv: Computation and Language.
Jurafsky, D., & Martin, J. (2022). Speech and Language Processing (3rd ed. draft).
Li, J., Sun, A., Han, J., & Li, C. (2022). A Survey on Deep Learning for Named Entity Recognition. IEEE Transactions on Knowledge and Data Engineering, 34(1), 50–70. https://doi.org/10.1109/tkde.2020.2981314
Liu, P., Yuan, W., Fu, J., Jiang, Z., Hayashi, H., & Neubig, G. (2022). Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Computing Surveys. https://doi.org/10.1145/3560815
Michael Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, & Luke Zettlemoyer. (2019a). BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. ArXiv: Computation and Language.
Jaison, Shermis, & Ark, Vander. (2012). The Hewlett Foundation: Automated Essay Scoring [Dataset]. Kaggle. https://kaggle.com/competitions/asap-aes
Ramshaw, L., & Marcus, M. (1995). Text Chunking using Transformation-Based Learning. ArXiv: Computation and Language.
Sang, E. T. K., & De Meulder, F. (2003). Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition. ArXiv: Computation and Language.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is All you Need. Neural Information Processing Systems, 30, 5998–6008.
Wang, Q., Fang, Y., Ravula, A., Feng, F., Quan, X., & Liu, D. (2022). WebFormer: The Web-page Transformer for Structure Information Extraction. Proceedings of the ACM Web Conference 2022. https://doi.org/10.1145/3485447.3512032
Yadav, V., & Bethard, S. (2019). A Survey on Recent Advances in Named Entity Recognition from Deep Learning models. ArXiv: Computation and Language.Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Michael Lewis, Luke Zettlemoyer, & Veselin Stoyanov. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. Cornell University – ArXiv. https://doi.org/10.48550/arxiv.1907.11692