
Occlusion by clouds can be a major inconvenience when trying to make use of satellite-based earth observation imagery. Being able to detect cloudy portions of images, infer cloudiness percentage, and generate cloud masks are all handy capabilities. Our approach to doing those things is to develop and use machine learning models to detect clouds. In this first-of-a-series post, we hope to whet your appetite for future posts by presenting a few quantitative results and some qualitative results from our effort. We also share some pointers to (work-in-progress) models that you can try for yourself.
The work in this post concerns Sentinel-2 L1C and L2A imagery.
The labeled cloud dataset
Our labeled dataset consists of 32 unique scenes in 25 unique locations. The scenes include all four seasons (though not every season is represented in every location).
These scenes cover many different biome types, ranging from Angkor Wat to Anchorage, from Tiawanacu to Timbuktu, and from Montana to Mohenjo-Daro.
Each scene is an entire Sentinel-2 tile. There are Sentinel-2 L1C and L2A versions of all scenes in the dataset.
The labels (polygons corresponding to cloudy areas of each image) were generated by our partners at CloudFactory using GroundWork.


This dataset has not yet been made publicly available, but we look forward to doing that soon.
Cloud detection model architectures
We used two architectures for the work in this post.
- FPN (concept by Lin et al., implementation by Adeel Hassan) with a ResNet-18 backbone
- CheapLab (concept and implementation by the present author)
The FPN architecture is a true deep-learning architecture with sophisticated high-level vision capabilities. The ResNet-18 backbone is relatively small and lightweight, but nonetheless, this architecture is much more suited for GPU inference than CPU inference.
By contrast, CheapLab is a shallow architecture that seeks to capture (be able to represent) the family of functions that includes standard normalized indices such as NDWI, NDCI, NDVI, et cetera. CheapLab has the advantage of not needing an explicit, prescribed threshold to distinguish between a positive (foreground) response and a negative (background) response as NDWI and the rest do. For CheapLab, that cutoff is fixed implicitly by the training procedure.
CheapLab models are quite small (about 40KB on disk) and are suitable for CPU-based inference.
The vital statistics for the models used in this work are as follows.
| Avg. Cloud Recall | Avg. Cloud Precision | Avg. Cloud F1 Score | |
|---|---|---|---|
| FPN L1C | 0.914 | 0.911 | 0.913 |
| CheapLab L1C | 0.810 | 0.848 | 0.826 |
| FPN L2A | 0.910 | 0.911 | 0.910 |
| CheapLab L2A | 0.796 | 0.872 | 0.832 |
Exploring cloud labeling results in four settings
In this section, we present qualitative results taken from looking at four different scenes. The four scenes consist of imagery taken over Ghana, Spain, Algeria, and the United Kingdom. These scenes are completely separate from any found in the training set (in fact, these locations are not found in the training set).
These results were produced using (respectively) an ensemble of two FPN models, an ensemble of three CheapLab models, and an ensemble of two FPN models plus three CheapLab models.
Accra, Ghana
Both types of models do a good job of detecting clouds in this scene. It can be seen that the ensemble of FPN models does a better job of detecting the wispy clouds over the ocean in the bottom-right of the image, while the ensemble of CheapLab models does a better job of completely covering the clouds over land near the bottom-right. The ensemble of both model types seems to retain many of the positives of both.

L2A FPN CheapLab FPN+CheapLab




In detail: A small inland water body
There is a small inland water body at the top left of the scene. Taking a close look at this water body, we find that CheapLab generates a number of false positives on/around this body while the FPN models do a nice job of differentiating between clouds and water. The ensemble of both model types inherits some false positives from CheapLab.

L2A FPN CheapLab FPN+CheapLab


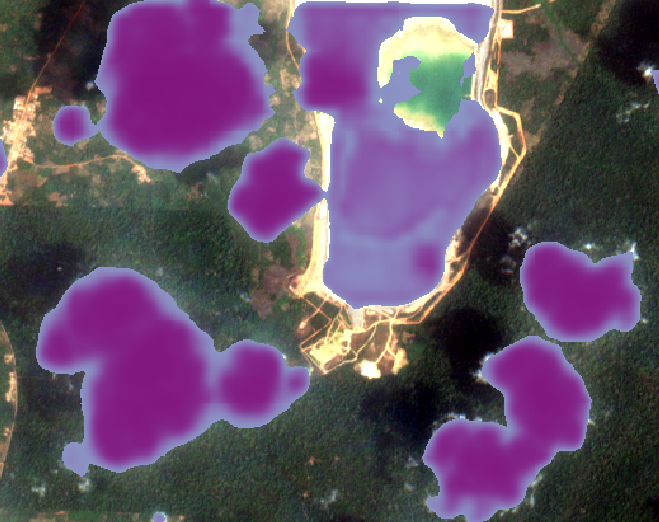

In detail: Wispy clouds over land
In this instance, CheapLab generally does a better job of completely covering wispy clouds over land.

L2A FPN CheapLab FPN+CheapLab




In detail: Wispy clouds over water
In contrast to the previous case, the FPN models do a better job of completely covering wispy clouds over ocean water.

L2A FPN CheapLab FPN+CheapLab




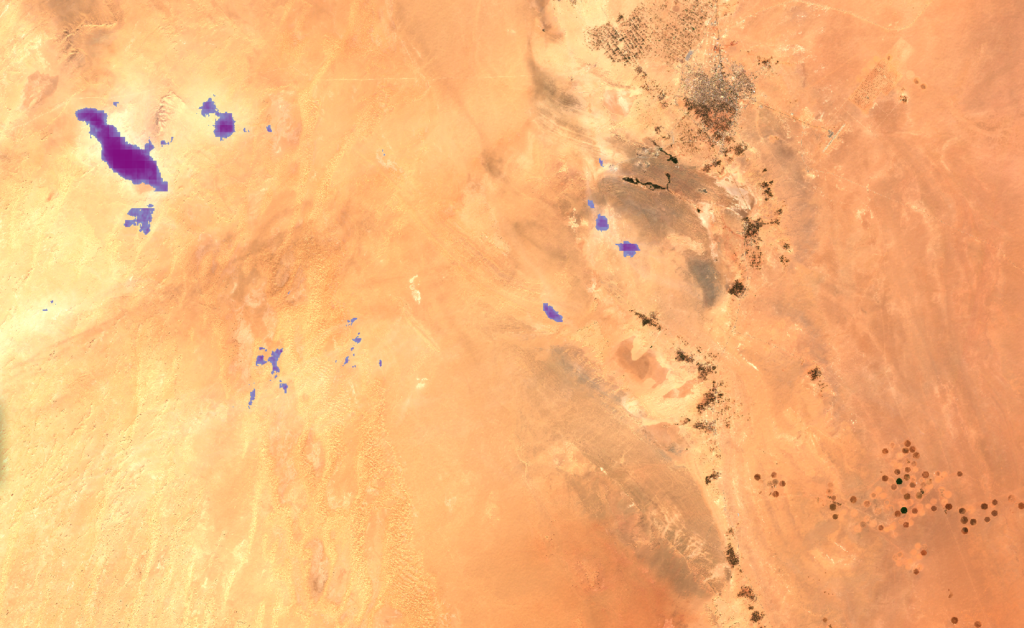
Adrar, Algeria
This image contains only a few wispy clouds. Both model types manage to detect the clouds, though the entire area of the wispy cloud in the upper-left is seemingly not covered by either. The CheapLab models seem to generate a few (possible) false positives in the right half of the image. The overall level of pixel intensity is much greater in this image than is typical in the training set, which may be a problem for both model types.

L2A 
FPN 
CheapLab FPN+CheapLab



Castellón, Spain
The FPN and CheapLab models both do a good job of detecting clouds above land. The CheapLab model does a better job of detecting the clouds over the ocean in the bottom-right. The predictions generated by the ensemble of FPNs and CheapLabs retains the over-water detection.

L2A FPN CheapLab FPN+CheapLab




In detail: Clouds over ocean
Here is a closer look at the clouds over ocean water seen in the bottom-right.

L2A FPN CheapLab FPN+CheapLab




In detail: Buildings
Looking closely, we can see that CheapLab generates some false positives on lightly-colored buildings while the FPN ensemble does not.

L2A FPN CheapLab 
FPN+CheapLab




Greenwich, London, UK
Both models do a good job of detecting clouds in this scene, though the FPN model does a better job completely covering the wispy cloud over the inland water body.

L2A FPN CheapLab FPN+CheapLab




Give it a try
The models described in this post were trained on the Sentinel-2 imagery from AWS, not imagery from SentinelHub. The models are designed for the former and wholly incompatible with the latter. Luckily, one can easily obtain imagery from AWS using the quay.io/jmcclain/sentinel-downloader docker image.
Download imagery
Given a GeoJSON polygon called polygon.geojson (preferably covering a very small area), one can type the following to download Sentinel-2 imagery covering the polygon.
docker run -it --rm -v $HOME/.aws:/root/.aws:ro -v /tmp:/input -v /tmp:/output quay.io/jmcclain/sentinel-downloader:1 --geojson /input/polygon.geojson --mindate 2019-01-01 --maxdate 2020-12-13 --minclouds 23.6 --maxclouds 38.1 --images 1 --output-dir /output
Notice that the directory $HOME/.aws on the host is mounted to /root/.aws in the container. This is because AWS credentials are needed to download from the requester-pays Sentinel-2 bucket. Notice that the directory /tmp on the host is mounted to both /input and /output in the container so that the input files must be there and the output files will go there.
The source code for the image can be found here if you wish to build it yourself.
Perform inference
Given compatible imagery, one can type the following to perform inference on it.
docker run --runtime=nvidia -it --rm -v /tmp:/input -v /tmp:/output quay.io/jmcclain/cloud-model:0 --infile /input/L2A-0.tif --outfile-final /output/final.tif --outfile-raw /output/raw.tif --level L2A --architectures cheaplab fpn-resnet18
Notice that this command assumes the existence of a suitable Nvidia graphics card and a properly configured Linux host.
One can invoke the container without any arguments to it to see additional usage instructions.
docker run --runtime=nvidia -it --rm -v /tmp:/input:ro -v /tmp:/output quay.io/jmcclain/cloud-model:0
The source code for the inference image can be found here, although the models needed to build the container are not in the repository. If you wish to, you can extract the models from the /workdir/models directory of the docker image discussed above and put them into the source tree so that you can rebuild the container.
Future installments
Reader interest will dictate the next installment in this series. What do you want to hear about? Some possible topics are listed below. Reach out to let us know, and feel free to suggest a topic not on this list!
- The Sentinel-2 Cloud Label Dataset
- Model Training Details
- Cloudless Imagery at Continent-Scale (On Inexpensive AWS Instances)
- Beyond Sentinel-2
- What About Cloud Shadows?