
Last month, we ran a week-long satellite imagery labeling competition in partnership with Radiant Earth as part of the most recent Cloud Native Geospatial Sprint. The organizers of the sprint were looking for a way to reach a broader audience and give non-technical folks a way to participate, since most of the event was focused narrowly on software engineering. Their idea was to run a labeling competition and produce an open dataset adhering to the SpatioTemporal Asset Catalog specification, a relatively new open standard for representing large geospatial datasets with a small but quickly growing list of public examples. After some brainstorming, we arrived at a simple idea: labeling clouds in freely available satellite imagery. After all, cloud masking remains an annoying issue in remote sensing research, and there aren’t many open datasets available that provide hand-labeled ground truth examples of cloud masks.
What I expected to happen was this: we would launch the competition, a handful of participants would show up the first day, and after a grueling week of tweeting and posting on LinkedIn, we’d wind up with 5-10 labeled satellite images. To be clear: that outcome would have been phenomenal. These images are enormous and often contain tortuously detailed cloud patterns that are exhausting to label by hand (and still extremely difficult to teach machines to recognize at an accuracy akin to humans).
Here are a few examples of what clouds actually look like in satellite imagery (notice how incredibly diverse they appear–some are well-defined while others wispy and translucent):





In fact, those are all sampled from a single image. Yeah, just one image contains that much diversity of cloud cover and almost half the image isn’t even obscured by clouds!

So, we can be forgiven for assuming that while a lot of work would get done, not a lot of data would be generated. We couldn’t have been more wrong.
Lesson #1: Prepare for success
What transpired next was a stupefying surprise. From the earliest moments of the competition, dozens of participants poured in and labels started appearing at a torrential rate that only seemed to increase as the week went on. Each image was broken up into 512×512 pixel “tasks,” which could be labeled independently, because Sentinel-2 scenes are far too large to label all at once. Our initial guess was that somewhere in the neighborhood of 5,000 such tasks would be labeled by the week’s end. But by the second day, we had already crested that number. In fact, labelers were moving so quickly, we struggled to add new images fast enough to keep them busy. By the end, over 75,000 tasks were completed, or somewhere around 2.3 million square kilometers mapped. That’s like, 19 billion classified pixels or so. Insane.
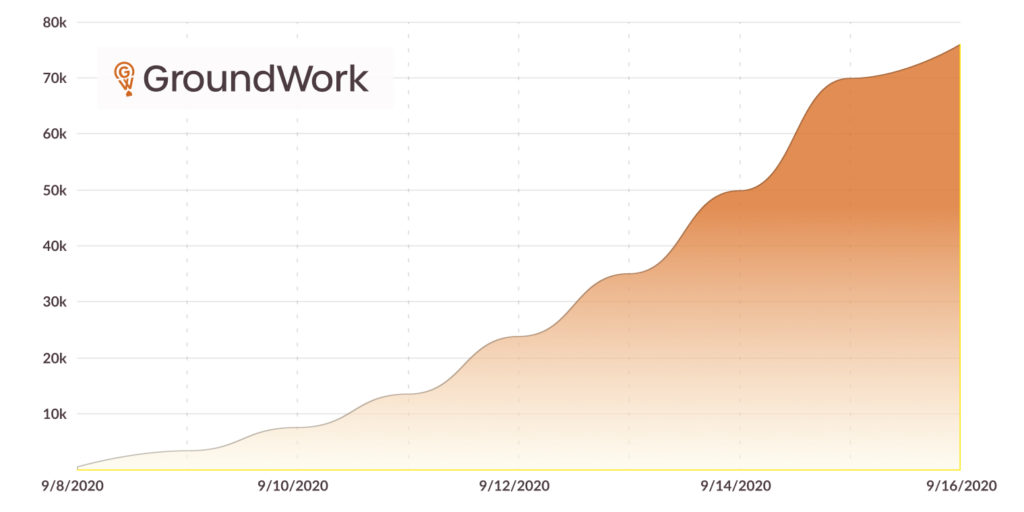
If we ever do this kind of project again (and I suspect we will), making sure we have an inhuman amount of raw data already prepared will be paramount. We may also consider a fixed amount of images that, once labeled, will trigger an end to the competition.
Lesson #2: Provide as much documentation as possible
A common theme in machine learning projects is that no task is simple, no matter how simple it sounds. We made a good decision to limit the labeling procedure to two very discrete classes: cloud and background. Traditionally, cloud shadows are often labeled as well (since they tend to skew the spectral signature of the earth’s surface and can therefore throw off statistical timeseries analysis). But simpler is always better when it comes to crowdsourcing information, and clouds are a relatively ambiguous “thing” to label. Often, they are thin and wispy, and you can see right through them. Sometimes they are extremely choppy, with lots of gaps that are technically not “cloud” but also aren’t large enough to really be considered background…

While we put together a training video with instructions, what we learned very quickly is that in the future, we should pair that with lots of visual examples that participants can constantly refer back to (either embedded in the application itself or in a supplemental document). We fielded lots of questions about how to appropriately label edge cases, but the truth is, for many labeling tasks there is no easy way to define a canonical answer. Different annotators will make slightly different decisions–the hope is that you collect a large and diverse enough dataset that a model does not overfit to one particular annotator’s bias and instead comes to a balanced, reasonable equilibrium.
Lesson #3: Aim for a sprint, not a marathon
People get tired. Machines do not. That’s why we want to train machines to do the tasks humans find tiring. But in order to train those machines, we have to put a bunch of people to work creating ground truth data, and that’s often a time-intensive, expensive, and soul-sucking endeavor. One of the biggest pieces of advice we got from contestants was that they wished the competition were shorter. There were several epochs throughout the week–periods of single-annotator dominance and massive swings in momentum. To be honest, it was very stressful to moderate–we could literally see when top-contenders went to sleep and when they woke up. We felt like we were working people to the bone, and apart from correlating with lower-quality work, it also just felt like an unintended and negative consequence of the competition format.
In the future, we’ll consider much shorter, focused competitions that allow a lot of people to work for a short period of time (perhaps a single 8-hour day) and then never have to think about it again. We suspect this will produce higher quality labels, but more importantly, it will be less harmful to top participants aiming for gold.
Next Steps
Naturally, because so much more data was produced than we anticipated, it’s going to take longer than expected to get this data cleaned and ready to be released. But that has always been our intention–we plan to work with Radiant Earth to publish this data on Radiant MLHub, where it can be accessed by anyone for any use, commercial or otherwise. If you’re interested in helping to sponsor the cleaning and publication of this data, please let us know–we’ve already fielded interest from at least one company that is volunteering their data engineering resources to help with the cause!
If you’d like to get involved please contact groundwork@azavea.com!