
100 years ago, less than half of the U.S. population lived in urban areas. Today, that proportion is closer to 84%.
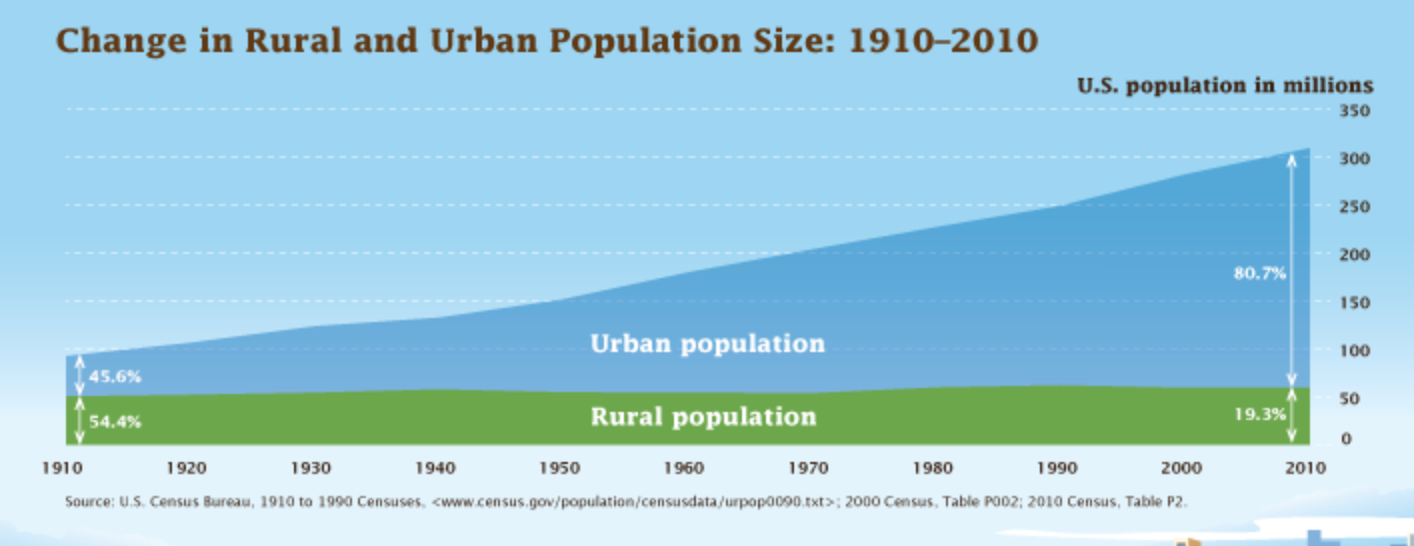
Rapid urban growth has put tremendous pressure on cities to adapt systems, services, and infrastructure, but while population dynamics are changing dramatically, the tools at cities’ disposal to account for and react to that change are struggling to keep up. Effective planning requires accurate information, and staying on top of an increasingly sprawling urban footprint is a tall task no matter how big your budget is. Historically, the best-run cities have used data to influence policy-making and enforcement, but traditional data-gathering methods are often prohibitively expensive to carry out at intervals appropriate for the pace of growth U.S. cities are experiencing today.
How cities are changing the way they collect data
In a past life, I used to sell tree inventory software to small cities across the country. “Urban forestry” as a profession and field of study is criminally under-valued; denser urban tree canopy is correlated with lower rates of crime, higher home values, and better health outcomes. But even the wealthiest cities can only afford to take stock of their tree inventory once a decade or so. Paying professional arborists to perform a survey on foot costs upwards of $4/tree — at that rate, the math simply doesn’t work if your goal is to understand change at an annual or even biannual level so you can react quickly and forecast effectively.
Instead, most urban forestry professionals are stuck planning annual budgets with comically out-of-date information or hardly any information at all. For a city like Philadelphia, where Azavea is headquartered, there are estimated to be around 150,000 street trees and millions more in parks — it would take more than a quarter of the city’s annual Parks and Recreation budget to inventory just the curbside trees. At that point, they’d have a wealth of actionable information and no money left to do anything about it.
In Philadelphia’s case, rather than spend many multiples of their entire annual budget on a comprehensive inventory, they leveraged street-level imagery to virtually walk the streets and demarcate the location of trees. In a few short months, they were able to inventory 35,000 trees using this method at a fraction of the cost of a traditional inventory.
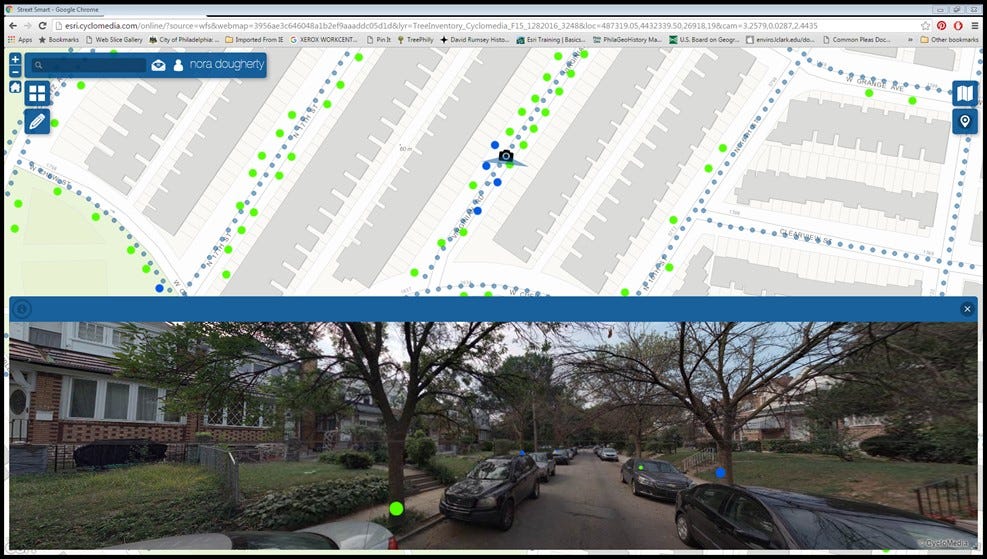
You may be thinking to yourself, “Wow, that sounds like an incredibly tedious and repetitive task,” and you’d be right — imagine spending hours at a time mindlessly marking the location of a tree and entering a few obvious details about it (e.g. alive/dead, planting location, approximate diameter, etc.). This is exactly the kind of challenge a deep learning model could be trained to perform effectively and at an inhuman pace.
With tens of thousands of labeled trees (and several images per tree as the car passes down the street), Philadelphia is sitting on a very valuable dataset of image and label pairs. Imagine, instead of paying for a partial inventory once every 5-10 years, the city could pay for street-level imagery collection once every year and simply run a model to inventory that information for effectively $0 marginal cost. It’s not hard to imagine that same principle extending to other valuable information like curb cutouts, crosswalks, street signs — even potholes.
The hard work is already done
As in the example of Philadelphia’s street trees, there are hundreds of critically important datasets cities collect and maintain as a matter of course that would make for exceptional training data for a supervised machine learning model. Whether it’s combining asset information like street tree locations with street-level imagery or geographic features like impervious surfaces with aerial imagery, cities have already invested millions of dollars in the most critical and time-intensive part of any machine learning process: creating and validating “ground truth” data.
The trend of population growth in urban areas does not show signs of slowing down, and the only way for cities to evolve policy quickly enough to match the demands of their changing constituency is to base decisions on more frequent, higher-fidelity data. In private industry, innovation like self-driving cars and checkout-less retail experiences are built on the back of hundreds of millions of dollars invested into creating exquisite training datasets. What I hope cities realize and start to act on is that they are, in fact, positioned to leverage that same emerging technology for themselves–and they’ve got a huge head start.