
In March of this year Azavea launched the Open Apparel Registry (OAR), an open-source web application and machine learning-based data processor that allows participants in the global apparel industry to publish their supplier lists and collaboratively build a global, searchable map of garment-production facilities.
A centralized, searchable map of facilities is a valuable tool, and one of the services that the OAR is designed to provide. Its most valuable contribution goes one step further: the OAR uses facility affiliations to connect brands and other contributors in ways that were previously impossible while also generating a unique OAR ID that can link facilities across systems.
The challenge
Apparel brands, multi-stakeholder initiatives, and other participants in the supply chain maintain their own lists of facilities. These lists are often compiled by staff without standard formatting and can often contain duplicate or otherwise “dirty” data. When attempting to compare lists compiled by different organizations and find the facilities common to them we are quickly confronted with several issues:
- File formats: Lists are often published only as PDF files which can make data extraction challenging and error prone.
- Transliteration problems: Inconsistencies when translating addresses with non-Roman characters into English text introduces variation in facility names and addresses.
- Unclear addresses: Facilities in less developed parts the world, where a significant portion of apparel manufacturing takes place, can have non-structured and non-specific addresses.
All facility lists contain a name, address, and country for each facility. Each of these three attributes presents some distinct challenges when trying to match records between the lists provided by different contributors:
- Name
- Names can include suffixes with differing abbreviations, e.g. “co” vs. “co.” vs “company.”
- Facility names can have small suffixes that are relevant, e.g “I” vs. “II.”
- Variations in transliteration when representing names from non-Roman characters.
- Address
- There are high quality algorithms for standardizing addresses but they don’t work with the ambiguous, loosely structured addresses seen in supplier lists.
- Address components inconsistently use abbreviations, e.g. “ST” vs. “STREET,” “BLV” vs. “BLVD” vs. “BOULEVARD.”
- Variations in transliteration when representing addresses containing non-Roman characters.
- Country
- There are variations in country names that must be standardized, e.g. “United Kingdom” vs. “Great Britain” vs. “Britain.”
Facility data examples
Included here are some examples of these issues taken from real, public supplier lists. Some supplier lists are available only as PDF files and processing them with text extraction tools can introduce errors. The two rows in the following table reference the same facility but the text extraction errors make the names difficult to compare.
| Name | Address |
|---|---|
| V .. FR AAS G M BH | ORTER STR. 6, 93233 |
| VFR AAS GMBH | ORTER STR, 6, 93233, GERMANY |
All of these rows in the next table refer to the same facility. Note all the variations in punctuation and spelling, and how values within the name and address fields can shift or disappear.
| Name | Address |
|---|---|
| Hela Clothing (Pvt) Ltd. Thihariya | 875 Rosimer Estate,Kandy Road,Thihariya,Nittambuwa |
| Hela Clothing Thihariya | 875 Rosimer Estate,Kandy Road,Thihariya, Kalagedihena, Sri Lanka |
| Hela Clothing (Pvt) Ltd. Thihariya | Hela Clothing (Pvt) Ltd. Thihariya, 875 Rosimer Estate, Kandy Road, Thihariya,Nittambuwa |
| Hela- Thihariya | No: 875 Rosimer Estate Kandy Road Thihariya |
| Hela Clothing-Thihariya | No 875, Rosimer Estate, Thihariya, Kalagedihena, Western |
| Hela Clothing (Pvt) Ltd. – Thihariya | No. 875 Rosimer Estate, Thihariya, Kalagedihena, Nittambuwa, Sri Lanka |
| HELA C LOTHING THIHARIYA | 875 ROSIMER ESTATE,KANDY ROAD,THIHARIYA, KALAGEDIHENA, SRI LANKA |
The two rows in the next table refer to two distinct facilities. Some key words in a facility name can be significant (“Washing Plant” in this case).
| Name | Address |
|---|---|
| Cutting Edge Industries Ltd. (Washing Plant) | 1612, South Salna, Salna Bazar Gazipur Sadar, Dhaka |
| Cutting Edge Industries Ltd. | 1612, Dakin Salna, Salna Bazar, Gazipur Sadar Dhaka |
Problems with conventional approaches
There are “fuzzy” search tools available for many databases and search indexes which could help us connect data in some of these situations, but these tools have trouble with properly handling minor, but significant, changes in facility names which require domain expertise to interpret properly. There are powerful tools for standardizing structured international addresses, but these tools have trouble interpreting the ambiguous and jumbled addresses that appear in real-world facility lists. We also run into issues of scale if we attempt the brute-force approach of individually comparing each contributed facility to every other known facility.

To deal with these issues quickly and efficiently we need a tool that can capture the knowledge of domain experts, find commonalities in jumbled text, and confidently compare large lists without the need to compare each individual entry.
Dedupe
Dedupe is a Python library that uses supervised machine learning and statistical techniques to efficiently identify multiple references to the same real-world entity.
Dedupe takes its name from its primary application, looking through a single set of records and attempting to find duplicates. The workflow of the OAR involves comparing a new set of records submitted by a contributor to an existing set of mapped facilities. Dedupe has first-class support for this type of workflow through the use of a gazetteer matcher.
How Dedupe works
We tell Dedupe about the fields in our data we want to compare and the type of each field. “Type” in this context does not refer to a traditional programming language data type but rather how the data in the field should be interpreted and compared. The dedupe documentation includes a list of these types. For the OAR, our field configuration is simple:
fields = [
{'field': 'country', 'type': 'Exact'},
{'field': 'name', 'type': 'String'},
{'field': 'address', 'type': 'String'},
]
Amazingly, there is not a great deal of configuration required beyond that list of fields. While choosing those types is important, the power and efficiency of the library is derived not from static configuration, but from interactive training. Dedupe can match large lists accurately because it uses blocking and active learning to intelligently reduce the amount of work required.
Blocking
Blocking cleverly avoids having to compare each individual record from one data set to each individual record in another by breaking the data into distinct groups.
Duplicate records almost always share something in common. If we define groups of data that share something and only compare the records in that group, or block, then we can dramatically reduce the number of comparisons we will make. If we define these blocks well, then we will make very few comparisons and still have confidence
— Dedupe documentation
Dedupe can create two types of blocks, index blocks and predicate blocks. Index blocks group records together by looking up their field values in an index built from the unique values of each field. These lookups are fast, but the index is costly in both construction time and memory size and the blocks it produces are limited to exact matches.
Predicate blocks are more clever and powerful. They are created by grouping records together that share the same features. Here is a simple example from the Dedupe documentation:

Dedupe includes tens of predicate functions that can be combined to create hundreds of different compound blocking rules. Rather than require us to carefully combine predicates by hand in a laborious trial-and-error process, Dedupe, instead, starts by selecting generally useful defaults based on the field types and then uses the active learning process to tune the predicates so they extract the most distinguishing features of our facility names and addresses.
Active learning
The key to any high performing supervised machine learning process is effectively encoding the knowledge of domain experts into training data. Dedupe collects this knowledge using an iterative, real-time training process that emphasizes collecting the most relevant feedback rather than requiring large quantities of labeled data.
Here is an abbreviated example of the interactive training session for our facility data:
root@8174a7f28009:/usr/local/src/dedupe# python oar_dedupe_example.py importing data... starting interactive labeling... country : kh name : grace glory (cambodia) garment ltd address national road 4, prey kor village, kandal country : kh name : grace glory (cambodia) garment ltd address : preykor village lum hach commune angsnoul district kandal province cambodia 0/10 positive, 0/10 negative Do these records refer to the same thing? (y)es / (n)o / (u)nsure / (f)inished y country : cn name : h u zh o u ti anbao d r e ss c o ltd address : west of bus station 318 road nanxun town huzhou city zhejiang province country : cn name : jiaxing realm garment fashion co. ltd. address : no. 619 shuanglong road xinfeng town nanhu district jiaxing city zhejiang 314005 1/10 positive, 1/10 negative Do these records refer to the same thing? (y)es / (n)o / (u)nsure / (f)inished n
(The source for this example is available in the OAR Github repository)
There are a few things to note in this example:
- We are shown both similar and wildly different records. It is important to collect both positive and negative examples.
- The training process can be exited at any time and suggests providing a mere 10 positive and 10 negative matches. Impressively, Dedupe can effectively match data when trained with just this small number of examples. For our production data set we labeled around 50 positive matches and 50 negative matches.
During this training process dedupe is learning two different things about our facility data:
- How best to convert a measure of the distance between 2 records into a match probability.
- Which blocking predicates produce the best separation of records into
similar groups.
Calculating the difference between strings
We previously discussed how blocking reduces the number of comparisons we have to make, but in order to find matches we must derive a numeric score that represents how similar or dissimilar each pair of records are. While dedupe includes support for different methods of comparing field values based on their type, and includes a pluggable system that allows for writing custom comparison functions, we have chosen to use simple string comparisons for our facility data.
At first glance, it is tempting to use the address field type, but that type uses a library tuned only for structured US addresses. Even if we were to write a custom field type that compared structured international addresses based on something like pypostal, which is designed to parse structured addresses from around the world, we would not get good match results for our particularly dirty, sometimes freeform facility address data.
To compare the similarity of our name and address strings, dedupe calculates the affine gap distance between them. Here is an illustration of how the affine gap distance between the strings “BLVD” and “BOULEVARD” is calculated.
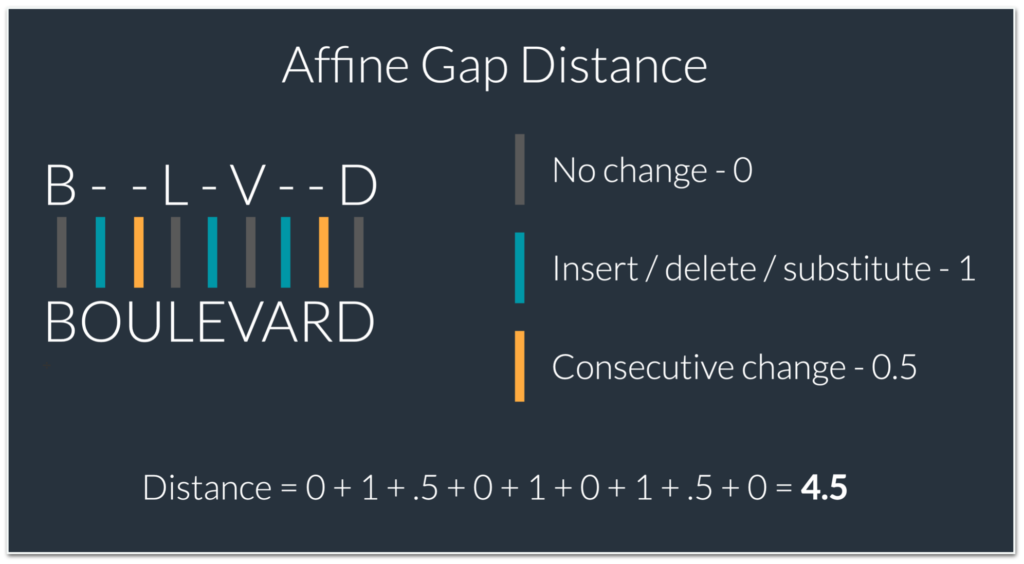
These calculated distances, by themselves, are not valuable on their own. Is “17” good or bad? An important part of dedupe’s active learning process is the conversion of these individual field distance measurements into a percentage probability that the records are a match.
If we supply pairs of records that we label as either being duplicates or distinct, then Dedupe will learn a set of weights such that the record distance can easily be transformed into our best estimate of the probability that a pair of records are duplicates.
— Dedupe documentation
Pre-processing our strings before comparing them maximizes the quality of our match results. In the OAR we remove extraneous whitespace and punctuation and pass our strings through unidecode in an attempt to convert international characters to suitable ASCII equivalents. This data cleaning ensures that Dedupe is detecting and optimizing for the differences in our text that matter.
The OAR facility matching process
Putting together everything we have discussed so far, here is a list of the high-level tasks that we have performed at development time to build a set of training data, and the high-level tasks that are performed each time a contributor submits a new list of facilities.
- Development Time
- Define variables (fields) for our facility records.
- Pre-process all data to produce clean strings.
- Deduplicate a concatenated collection of public facility lists.
- Train a gazetteer matcher with ≈ 50 positive and ≈ 50 negative labels.
- Save the labeled pairs and commit that training data to the repository.
- Runtime
- Define variables (fields) for our facility records.
- Pre-process all data to produce clean strings.
- Load the saved, labeled pairs.
- Train a new gazetteer matcher with the latest list of facilities.
- Match the contributed facility records. Auto-accept matches with 80% confidence or greater.
- Present matches between 50% and 80% confidence to the contributor for confirmation in a web UI.
Our dataset is small enough that we can efficiently train models and match data in memory. As the OAR grows we can maintain performance by scaling up the size of the machines performing the work, or use Dedupe’s support for working with large datasets.
The results
In production the performance of our Dedupe models has met our highest expectations. Here are a few examples of some challenging matches that our models have handled.
confidence | 0.50 name | Manufacturing Sportwear JSC - Thai Binh Br - Fty No 8 name | Manufacturing Sportwear JSC. (Thai Binh No. 8) address | Xuan Quang Industrial Cluster, Dong Xuan Commune Thai Binh Thai Binh Vietnam address | Lot With Area 51765.9 M2 Xuan Quang Industrial Cluster Dong Xuan Commune Dong Hung District Thai Binh
In the example above there are both significant differences and commonalities in the addresses. The low score is just above our threshold for presenting this likely match to the contributor for confirmation.
confidence | 0.61 name | Pratibha Syntex name | Patibha address | Plot No. 4, Industrial Growth Centre, Kheda Pithampur, Dist. Dhar, Indore, Madhya Pradesh address | Plot No. A-15 & 16, Apparel Park Phase-II, Special Economic Zone, Pithampur, Dist. Dhar Indore Madhya Pradesh
Above is an example of another low-scoring match that would be presented to the contributor for confirmation. The trained model picked up on the similarities between the significantly different addresses but we need some additional domain expertise to confirm that these are likely two distinct facilities.
confidence | 0.61 name | Orient Craft Limited name | Orient Craft Ltd (Freshtex) address | Plot No. 15, Sector 5, IMT Manesar 122050 Gurgaon Gurgaon Haryana address | Plot No 15 Sector - 5 Imt Manesar Gurgaon - 122050
The relatively low score on these very similar records highlights the fact that our model has learned that names with a suffix have an increased probability of not matching.
confidence | 0.89 name | Anhui Footforward Socks Co., Ltd. name | Anhui Footforward Socks Co. Ltd. address | West Baiyang Road, Economic Development Zone,, Huaibei, Suixi, Anhui address | West Baiyang Road,Suixi Economic Development Zone,Huaibei,Anhui,China
This automatically accepted match is a good example of the benefits of Dedupe’s string matching approach. Unstructured addresses with sections appearing in differing orders can be matched with confidence.
confidence | 0.89 name | PIC (Production International Company) name | PIC1 (Production International Company 1) address | Croisement Aousja El Alia, Aousja, Bizerte, Tunisia address | Croisement Aousja El Alia Bizerte
This automatically accepted match may be a false positive. The differences in the names may signify a different facility. No statistics-based approach can be correct 100% of the time.
Quality control
Our Dedupe models will make mistakes. We have built moderation tools into the Open Apparel Registry that allow our administrators and advisors the ability to refine the results. In the future, we will be able to feed these corrections back into the model as additional training data.
Closing thoughts
Dedupe is the core of the technical success of the Open Apparel Registry. The public connections it is helping stakeholders in the apparel industry make between brands and suppliers is having real, positive impacts.
I would like to thank the entire OAR Team for their hard work and dedication to this rewarding project and all the contributors and maintainers of Dedupe for graciously sharing their work.