
This summer, Jean joined the team as an Azavea Open Source Fellow to work on Grout, a flexible-schema framework for geospatial apps. The Azavea Open Source Fellowship program is a 12-week professional training fellowship that matches software engineering fellows with open source projects at Azavea.
Why generalize data entry and storage for records with a geospatial component? By empowering non-technical administrative users to directly define and modify what information to track in the system, Grout can then take care of the rest, providing cross-platform validated data entry forms as well as refined and fast server-side search to support analysis and visualization of the stored data, whatever it may describe. Read on to learn how Grout combines the flexibility of unstructured data storage with the reliability of schema validation and the robust geospatial function support of PostGIS to make recording and using data from the field easy and fun.
Why build apps with flexible schemas?
Database migrations eat up time and money
One common frustration with building geospatial applications is that it’s hard to change your data requirements, or what a database designer would call your schema. Say you’re building an app to track sightings of outdoor cats in your neighborhood (in West Philly, it’s hard to keep track of them all). Maybe you start off with a cat table whose schema includes columns like Name, Age, Color, Geom (corresponding to the location you saw the cat), and Breed:

| Name | Age | Color | Geom | Breed |
| Tabitha | 10 | Brown | (39.945, -75.218) | Tabby |
| Abby | 5 | Brown | (39.947, -75.225) | Abyssinian |
| Bobby | 8 | Grey | (39.953, -75.211) | Bobtail |
But while building the application you realize that you don’t really want to store a cat’s Age. Instead, you want to store Date of Birth, since you can use that to derive the Age:
| Name | Color | Geom | Breed | |
| Tabitha | Brown | (39.945, -75.218) | Tabby | |
| Abby | Brown | (39.947, -75.225) | Abyssinian | |
| Bobby | Grey | (39.953, -75.211) | Bobtail |
If you’re use a relational database like PostgreSQL to store your data, changing your schema like this requires writing a database migration, a custom script that can alter the definition of the database table and change the data in the database.
Database migrations are not only tedious to write, but more importantly, they can slow down the pace of development and strain the relationship between partners and engineers. If changing the system is painful, engineers will want to change the system as infrequently as possible, meaning that partners need to have their data requirements figured out up front before beginning development. Plus, any changes to the system that partners find out midway through development will require that engineers stop whatever they’re working on in order to rearrange the database schema. Add it all up, and you get slower velocity and an potentially combative relationship between the designers and the users of a migration-based system.
Key-value datastores sacrifice integrity for flexibility
One way to get around database migrations is to use a key-value datastore. Key-value datastores like Amazon’s DynamoDB get around the problem of database migrations by storing unstructured data, meaning that each entity in your database is stored as a blob of data without a strict schema definition. Entities are typically stored in a hash structure called a document, where any type of field is allowed. Here’s what the table above might look like in a key-value datastore:
{
"cats": [
{
"Name" : "Tabitha",
"Date of Birth": "2015-07-01",
"Color": "brown",
"Geom": [39.945, -75.218],
"Breed": "Tabby"
},
{
"Name" : "Abby",
"Date of Birth": "2012-06-08",
"Color": "brown",
"Geom": [39.947, -75.225],
"Breed": "Abyssinian"
},
{
"Name" : "Bobby",
"Date of Birth": "2014-12-15",
"Color": "grey",
"Geom": [39.953, -75.211],
"Breed": "Bobtail"
}
]
}
Now, if you want to change a field like Date of Birth again, you don’t have to write a database migration. You can just add a new cat to the cats array while including the new fields you want. Easy, right?
Not so fast! There are two main downsides to this approach:
- The structure of the data is ambiguous. When a client retrieves a cat from the database, there’s no guarantee what fields are going to be included, since the cat was never validated against a schema.
- Geospatial querying becomes harder. Currently, key-value datastores tend not to have as strong support for querying geospatial data as PostgreSQL does through the PostGIS extension. With a key-value datastore, we lose some ability to ask specific questions like “how many outdoor cats live between Baltimore Avenue on the north and Kingsessing Avenue on the south?”
Grout: the best of both worlds
What if we could combine the geospatial muscle and built-in schema validation of a relational database like PostgreSQL with the flexibility of a key-value datastore like DynamoDB?
Enter Grout, a flexible-schema framework for geospatial applications. Grout uses a custom data model to embed a key-value datastore inside of a PostGIS-enabled PostgreSQL database. Using versioned schemas, Grout allows an admin user to easily change the database schema while still verifying that new records match that schema.
The promise of flexibility
Flexible schemas promise a few important advantages for all stakeholders involved in application development:
- Partners don’t have to have all the data up front, and can do data discovery as the engineers are building the application.
- Site administrators can easily change data requirements without having to bug developers to write migrations.
- Developers can forget about the database and focus on what really matters: presenting the data to users in the most useful way possible.
Let’s take a closer look at how Grout makes good on these promises.
Flexible schemas, the Grout way
Organizing records and schemas

Grout is centered around Records, which are just entities in your database. A Record can be any type of thing or event in the world, although Grout is most useful when your Records have some geospatial and temporal component (like cat sightings).
Every Record contains a reference to a RecordSchema, which catalogs the versioned schema of the Record that points to it. This schema is stored as JSONSchema, a specification for describing data models in JSON.
Finally, each RecordSchema contains a reference to a RecordType, which is a simple container for organizing Records. The RecordType exposes a way to reliably access a set of Records that represent the same type of thing, even if they have different schemas. As we’ll see shortly, RecordTypes are useful access points to Records because RecordSchemas can change at any moment.
Versioned schemas can change easily
In Grout, RecordSchemas are append-only, meaning that they cannot be deleted. Instead, when you want to change the schema of a Record, you create a new RecordSchema and update the version attribute.
For a quick example, say that we want to accomplish the same schema change as in the cat example above, changing the Age field to a Date of Birth field. A simplified example of the initial schema object might look something like this:
{
"version": 1,
"next_version": null,
"schema": {
"Name": {
"type": "string"
},
"Age": {
"type": "integer"
},
"Color": {
"type": "string"
},
"Breed": {
"type": "string"
}
}
}
A real-world schema would be more complicated than this example, but the most important properties are still there:
- This is the first version of the schema (its
versionis1) - There is no more recent version than this one (its
next_versionisnull) - The schema definition itself is stored in the
schemakey, which defines all of the available fields
Now say we want to change Age to Date of Birth. Instead of changing the schema directly, we’ll create a new schema. Grout will automatically set version: 2 and next_version: null for this updated schema:
{
"version": 2,
"next_version": null,
"schema": {
"Name": {
"type": "string"
},
"Age": {
"type": "integer"
},
"Date of Birth: {
"type": "string",
},
"Color": {
"type": "string"
},
"Breed": {
"type": "string"
}
}
}
In addition, Grout will update the initial schema to set next_version: 2:
{
"version": 1,
"next_version": 2,
"schema": {
…
}
}
Now, when a user searches for Records in the cat RecordType, Grout can find the most recent schema by looking for the RecordSchema where next_version: null. This preserves a full audit trail of the RecordSchema, allowing us to inspect how the schema has changed over time.
Want to take a closer look? If you’re familiar with Python and Django, see the Grout models to get a more detailed view of the Grout data model.
Flexible schemas in action
Using the Grout data model, you can edit schemas on the fly and watch your changes propagate immediately to your application. For a quick demo, watch as the auto-generated filters in the left sidebar change when an admin user edits the schema to add a “Full text” field:

Improved flexibility and integrity
By associating Records with versioned RecordSchemas, Grout allows for flexible schemas and strong data integrity at the same time. Grout can validate incoming against Records against their RecordSchema while still allowing the overall schema to change at any time. Plus, all of the data is stored in key-value format inside of a relational database, powered by the full geospatial muscle of PostGIS.
The Grout stack
Open source, top to bottom
Grout leverages a number of open source tools to combine the muscle of relational databases with the flexibility of key-value stores.
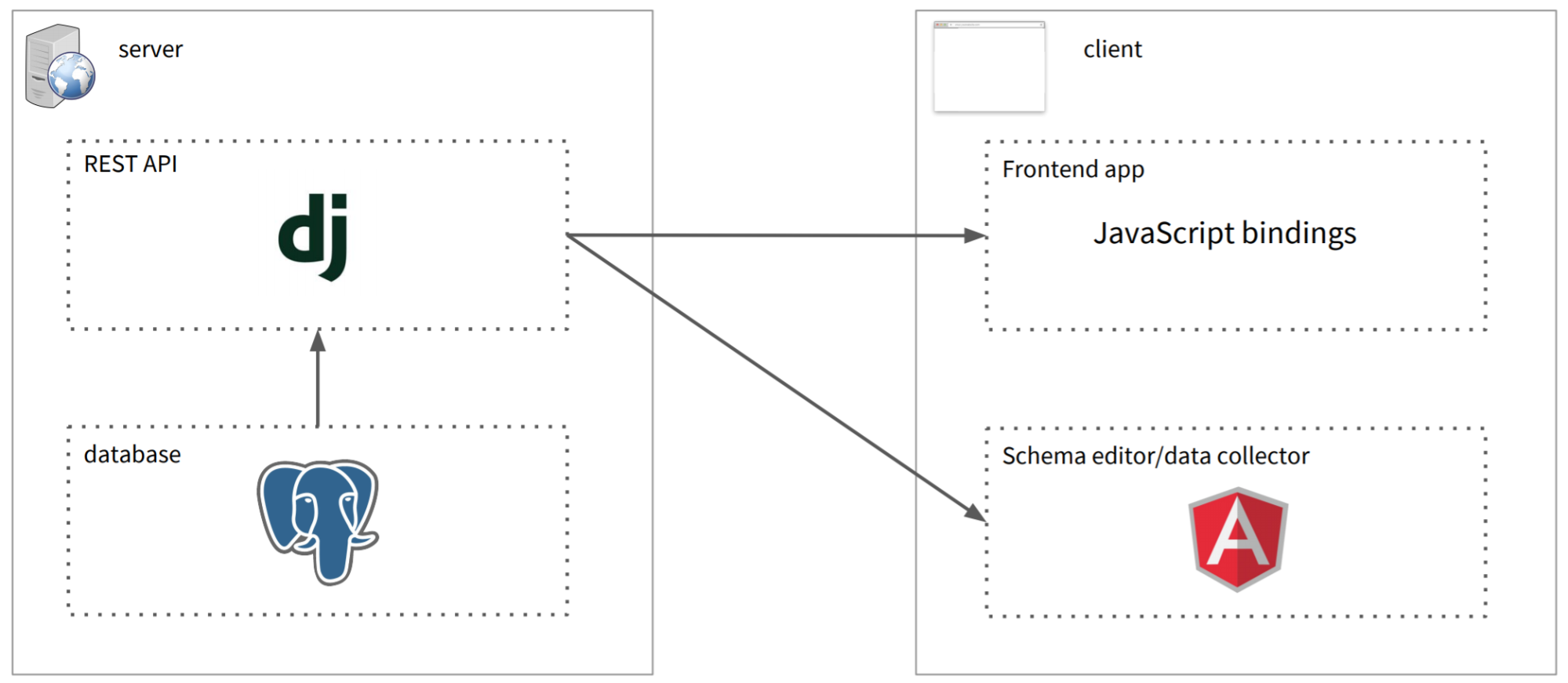
On the server side, every Grout application sits on top of a PostgreSQL database, which provides geospatial support through the PostGIS extension. While the flexible data component of a Record is stored in an unstructured JSONB field, its geometry is stored as a traditional SQL column. This means that Records can be associated with any geometry type, including Points, Polygons, and LineStrings, and Grout can use geospatial PostGIS queries to see if a Record’s geometry intersects with another geometry, like a polygon or a bounding box.
The database is made available to the world through a Django REST API running on top of Django REST Framework. In addition validating incoming Records using the appropriate RecordSchema, the Grout API can also handle complex queries of the data, including nested filtering and search of the flexible fields.
On the client side, any frontend library can interface with the Grout API, but we’re working on a set of JavaScript bindings to make it even easier to query from the browser. Grout also has an optional Schema Editor backend that runs on AngularJS and can be deployed as a standalone static app, allowing non-technical users to collect data and edit schemas on the fly.
Deploy your own Grout stack
We’ve put together a few different repos to help you deploy your own Grout stack:
- Grout, the core application.
- Grout Server, an easily-deployable Django project that provides an API server instance running Grout.
- Grout Schema Editor, a standalone app providing an admin backend to a Grout Server that can help non-technical users easily edit schemas and collect data.
- JavaScript Bindings, coming soon!
The future of Grout
Grout is a growing project, and lots of work is planned for the future. Next on our plate:
- Continue to improve the schema editor
- Test and distribute JavaScript bindings
- Support alternate backends
- Build more applications on top of Grout
Does this pique your interest? We welcome contributions! Open an issue or a pull request on GitHub.
Jean Cochrane worked on Grout as part of the 2018 Open Source Fellowship at Azavea. Learn more about the Azavea Open Source Fellowship program.