
The GeoTrellis team recently had an opportunity to benchmark GeoMesa and GeoWave, two big data projects aimed at providing distributed persistence and analysis for geospatial applications based on Apache Accumulo. We used GeoDocker, a collection of Docker containers, to overcome challenges associated with developing, testing, and deploying these projects.
Benchmarking Big Data Projects
In order to provide a meaningful benchmark we had to treat the project as if it was a production application based on these technologies. It had to be developed, tested, and deployed to AWS facing all the DevOps challenges that come with the territory. We leveraged Docker to mitigate these challenges and curated a collection of Docker containers we’ve released as GeoDocker.
![]() As is often the case with applications of this sort (multiple interdependent systems which, in production, live on different machines), a fully functioning cluster is presupposed for even basic operations. For instance, Accumulo requires both HDFS and ZooKeeper to be configured and running to even initialize. Maintaining a local installation of these resources is guaranteed to introduce unnecessary pain. It increases complexity, slows down the development workflow, and introduces opportunities for environment incompatibilities.
As is often the case with applications of this sort (multiple interdependent systems which, in production, live on different machines), a fully functioning cluster is presupposed for even basic operations. For instance, Accumulo requires both HDFS and ZooKeeper to be configured and running to even initialize. Maintaining a local installation of these resources is guaranteed to introduce unnecessary pain. It increases complexity, slows down the development workflow, and introduces opportunities for environment incompatibilities.
Why use Docker?
Using Docker allows us to sidestep these difficulties by encapsulating configuration and scripting changes to state. This can ensure a consistent and predictable state that can be versioned and shared. Because these components are designed around the socket interface, they provide a natural boundary on which we can decompose their dependency.
Thus, the expectation is that each Docker container will listen on a network port and possibly communicate with other containers over their socket. Currently the existing GeoDocker images provide a “good enough” state to start development and can be extended and and re-used for deployment.
Customizing GeoDocker
A customized configuration of GeoDocker may be handled in a few ways:
- Environment variables passed to the container for minimally required configurations.
- Volume mounting configuration files when they are available from existing shared resources.
- Using GeoDocker image as base to bring in additional artifacts and configurations.
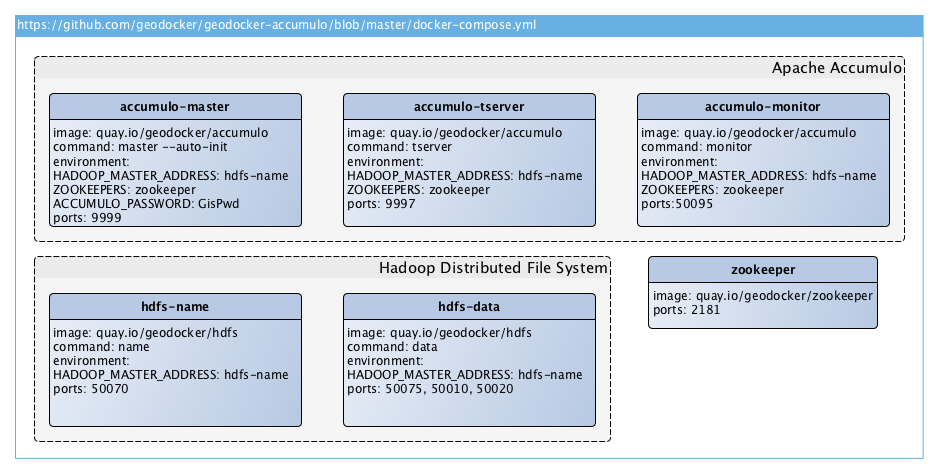
Each GeoDocker repository is responsible for a single component, e.g. Accumulo or HDFS, which is versioned and published independently. Each repository also contains a <a href="https://github.com/geodocker/geodocker-accumulo/blob/master/docker-compose.yml" target="_blank">docker-compose</a> file which launches a minimal cluster, bringing in dependencies as necessary. These docker-compose files are suitable for development and integration testing in a projects that require that piece of infrastructure.
Keep an eye out for Part 2…
Next we need to see exactly how we can use these Docker containers to deploy our application on top of AWS. In part 2, we’ll look at the tricks we used to overcome the problem of resource discovery on AWS.