
Task Context
The Azavea Geospatial Insights team recently had the opportunity to work with the World Bank, where we developed a national road safety platform for the Philippines. The goal of the platform is the eventual reduction of traffic crashes, which currently account for approximately 3% of Philippine GDP, by tracking and analyzing traffic incident data.
The data collection and analysis capabilities available in this platform seek to give traffic analysts the tools necessary for determining actionable direction to infrastructure improvements, thus increasing road safety nationwide.
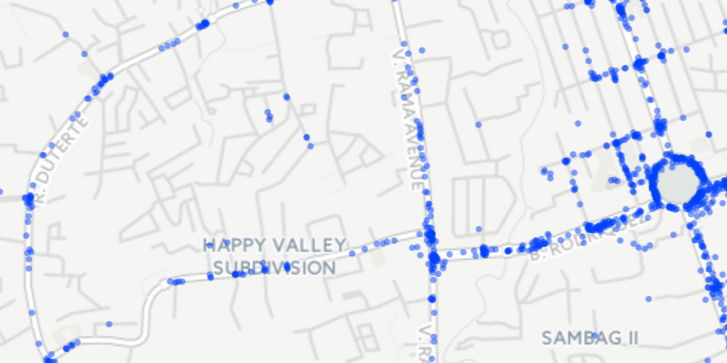 Crashes in Cebu, Philippines
Crashes in Cebu, Philippines
There were many technical challenges encountered while implementing this platform, and this post examines one of them:
-
How to process the traffic incident data and align it to the road network in order to locate the individual road segments and intersections that have historically seen the largest amount of traffic crashes
This post also discusses the implementation of some of the performance enhancements that were required in order to efficiently produce these results on a large, nationwide data-set.
Background Info
We chose Python to develop this feature, in part due to the excellent Python libraries for geospatial programming: Shapely and Fiona. These libraries are essentially wrappers for GEOS and OGR, respectively, which provide clean, Pythonic interfaces for performing the processing, while still keeping the performance capabilities of the underlying libraries. Fiona is used for reading and writing vector files (here we’re using Shapefiles), while Shapely is used for doing the manipulation and analysis of the geometric objects.
The desired output of this process is a Shapefile containing traffic intersections and road segments, split to a defined maximum length, each containing yearly aggregations of all crashes that occurred on those sections of road. A CSV is also output containing this information and is used to feed into a machine-learning algorithm to identify statistically significant Black Spots — a term used in road safety management for indicating areas with high concentrations of crashes.
In the platform, the Black Spot output is used to generate traffic enforcer reports, providing enforcers with a summary of areas that should be monitored for a given shift. The machine-learning and report generation components of this process aren’t detailed in this post, since the focus is on the Python code required to generate the Shapefile/CSV of aggregated crash data.
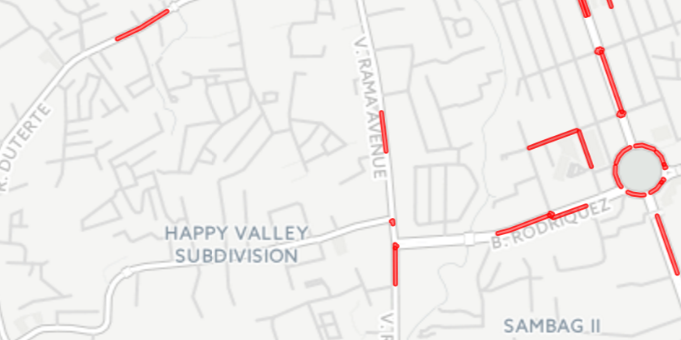 Black Spots in Cebu, Philippines — areas with high concentrations of crashes
Black Spots in Cebu, Philippines — areas with high concentrations of crashes
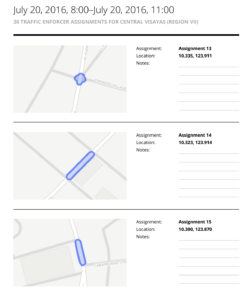 Traffic enforcer assignment report
Traffic enforcer assignment report
Workflow outline
- Read in OpenStreetMaps (OSM) roads Shapefile
- Identify intersection points
- Buffer intersection points
- Extract component line segments
- Split long lines
- Read in crash data
- Matchup crashes to nearest segment or intersection
- Calculate crashes per year aggregations for each segment/intersection
- Write out Shapefile and csv with aggregated data
The code discussed here is not specific to the Philippines, nor specific to traffic crashes. It’s designed to allow for aggregating counts of any point data to any desired region, and has many possible applications.
For the purpose of this walk-through, we’ll be using crash data in Philadelphia for the years spanning 2008-2012. This data was collected via PennDOT and is available here: https://github.com/dmcglone/philly-crash-data.
1. Read in OpenStreetMaps (OSM) roads Shapefile
There are several good sources of OpenStreetMap extracts including:
The Philadelphia extract contains approximately 130,000 roads.
 Philadelphia OpenStreetMap road network
Philadelphia OpenStreetMap road network
Reading in data from an OpenStreetMap Shapefile is a straightforward task using Fiona. The following code opens the Shapefile and iterates over each road, keeping only the highways, and appends Shapely objects to a list for use later. The filtering logic looks a little strange, because it needs to work with multiple data sources. When inspecting the Philippines OSM data and the Philadelphia OSM data, it became apparent that the definition of a highway was defined in slightly different ways. This code works for both sources, but there’s a chance the logic would need to be modified to account for a region that has an alternative set of attributes.
shp_file = fiona.open(roads_shp_path)
roads = []
for road in shp_file:
if should_keep_road(road):
roads.append(shape(road['geometry']))
def should_keep_road(road):
if ('highway' in road['properties']
and road['properties']['highway'] is not None
and road['properties']['highway'] != 'path'
and road['properties']['highway'] != 'footway'):
return True
if ('class' not in road['properties'] or road['properties']['class'] == 'highway'
and road['properties']['bridge'] == 0
and road['properties']['tunnel'] == 0):
return True
return False
2. Identify intersection points
 Philadelphia road intersections
Philadelphia road intersections
In order to find the intersections, combinations of each pair of roads are created, and the Shapely intersection function is called on each. The roads may intersect at either a point, multiple points, a line, multiple lines, or even more complicated configurations. For brevity, only a few types of intersections are shown in the following code. In each case, we’re collecting every point involved in the intersection. Finally, a unary union is performed on the set of points to remove any duplicates.
def get_intersections(roads):
intersections = []
for road1, road2 in itertools.combinations(roads, 2):
if road1.intersects(road2):
intersection = road1.intersection(road2)
if 'Point' == intersection.type:
intersections.append(intersection)
elif 'MultiPoint' == intersection.type:
intersections.extend([pt for pt in intersection])
elif 'MultiLineString' == intersection.type:
multiLine = [line for line in intersection]
first_coords = multiLine[0].coords[0]
last_coords = multiLine[len(multiLine)-1].coords[1]
intersections.append(Point(first_coords[0], first_coords[1]))
intersections.append(Point(last_coords[0], last_coords[1]))
return unary_union(intersections)
3. Buffer intersection points
Once the intersection points are obtained, we need to create a buffer around them using a desired number of map units. These buffers will be used to find the sections of road involved in a particular road intersection. This is necesarry, because we want to define a road intersection not only as the point itself, but also the surrounding road area, since a crash at an intersection doesn’t always occur at exactly the single intersection point.
def get_intersection_buffers(intersections, intersection_buffer_units):
buffered_intersections = [intersection.buffer(intersection_buffer_units)
for intersection in intersections]
return unary_union(buffered_intersections)
Spatial indices are necessary to perform fast spatial lookups. Here we are creating an R-tree index of the intersection buffers which is later used for efficiently finding the intersecting road segments.
int_buffers_index = rtree.index.Index()
for idx, intersection_buffer in enumerate(int_buffers):
int_buffers_index.insert(idx, intersection_buffer.bounds)
4. Extract component line segments
The next step is to divide up each road into segments that overlap the intersection buffers from the previous step, and sections that are not part of any road intersection (the intersection buffer overlap is subtracted out). All segments relevant to a single intersection are then union-ed together and treated as a single geometry for later aggregation purposes. The intersection buffer spatial index is used here to be able to quickly find these intersections.
segments_map = {}
non_int_lines = []
for road in roads:
road_int_buffers = []
for idx in int_buffers_index.intersection(road.bounds):
int_buffer = int_buffers[idx]
if int_buffer.intersects(road):
if idx not in segments_map:
segments_map[idx] = []
segments_map[idx].append(int_buffer.intersection(road))
road_int_buffers.append(int_buffer)
if len(road_int_buffers) > 0:
diff = road.difference(unary_union(road_int_buffers))
if 'LineString' == diff.type:
non_int_lines.append(diff)
elif 'MultiLineString' == diff.type:
non_int_lines.extend([line for line in diff])
else:
non_int_lines.append(road)
int_multilines = [unary_union(lines) for _, lines in segments_map.items()]
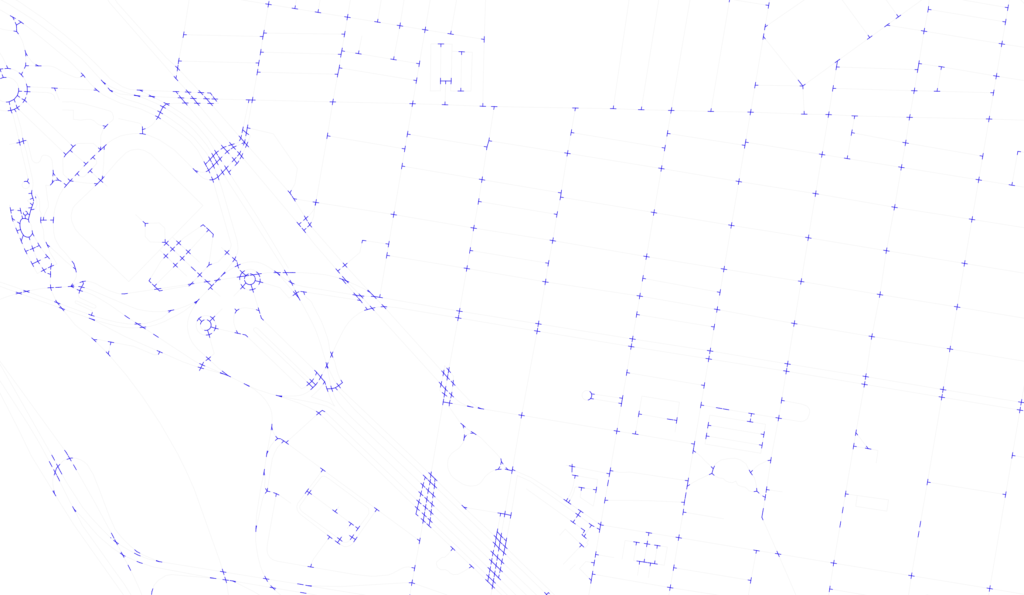
Intersection multi-lines
Non-intersection lines
5. Split long lines
Now we have a list of small intersection areas containing relevant segments, and a list of long stretches of road that aren’t broken up by intersections. It’s desirable to split up these long sections of road into smaller segments in order to provide more local aggregation results. This is because it is much more useful for a traffic analyst to know which small areas of a road are problematic, rather than knowing that an entire stretch of road is problematic, because then interventions can more effectively be put into place. The following code recursively splits the line in half until it is shorter than the maximum desired length.
def split_line(line, max_line_units):
if line.length <= max_line_units:
return [line]
half_length = line.length / 2
coords = list(line.coords)
for idx, point in enumerate(coords):
proj_dist = line.project(Point(point))
if proj_dist == half_length:
return [LineString(coords[:idx + 1]), LineString(coords[idx:])]
if proj_dist > half_length:
mid_point = line.interpolate(half_length)
head_line = LineString(coords[:idx] + [(mid_point.x, mid_point.y)])
tail_line = LineString([(mid_point.x, mid_point.y)] + coords[idx:])
return split_line(head_line, max_line_units) + split_line(tail_line, max_line_units)
6. Read in crash data
Now that we have the road network broken up into small units, it’s time to read in the crash data in order to determine where the crashes occurred. The crash data is in a CSV format, and is read in via a DictReader. The relevant columns are the X and Y coordinates, and the date/time in which the crash occurred. These column names are passed in as parameters to enable the code to work on any CSV that includes these three types of columns. A projection partial function is also defined here in order to ensure the road and crash spatial coordinate systems are aligned.
project = partial(
pyproj.transform,
pyproj.Proj(record_projection),
pyproj.Proj(road_projection)
)
records = []
min_occurred = None
max_occurred = None
with open(records_csv, 'rb') as records_file:
csv_reader = csv.DictReader(records_file)
for row in csv_reader:
try:
parsed_dt = parser.parse(row[col_occurred])
occurred = parsed_dt if parsed_dt.tzinfo else tz.localize(parsed_dt)
except:
continue
if not min_occurred or occurred < min_occurred:
min_occurred = occurred
if not max_occurred or occurred > max_occurred:
max_occurred = occurred
records.append({
'id': row[col_id],
'point': transform(project, Point(float(row[col_x]), float(row[col_y]))),
'occurred': occurred
})
7. Matchup crashes to nearest segment or intersection
Next we need to find the closest segment to each crash and build up a dictionary, mapping segments to relevant crashes. Another spatial index is used here to be able to quickly find all buffered crashes within each segment.
segments_index = rtree.index.Index()
for idx, element in enumerate(combined_segments):
segments_index.insert(idx, element.bounds)
segments_with_records = {}
for record in records:
record_point = record['point']
record_buffer_bounds = record_point.buffer(match_tolerance).bounds
nearby_segments = segments_index.intersection(record_buffer_bounds)
segment_id_with_distance = [
(segment_id, combined_segments[segment_id].distance(record_point))
for segment_id in nearby_segments
]
if len(segment_id_with_distance):
nearest = min(segment_id_with_distance, key=lambda tup: tup[1])
segment_id = nearest[0]
if segment_id not in segments_with_records:
segments_with_records[segment_id] = []
segments_with_records[segment_id].append(record)
8. Calculate crashes per year aggregations for each segment/intersection
We now have a list of crashes that are relevant to each individual road section, and can perform yearly aggregations. A schema is first built up, which will be used for later writing out the Shapefile and CSV. It’s a dynamic schema, since the number of aggregations calculated is determined by how many years of data are available. The columns are labeled as follows: t0records [records between the maximum occurred date and one year prior], t1records [records between two years prior and one year prior], etc.
schema = {
'geometry': 'MultiLineString',
'properties': {
'id': 'int', 'length': 'float', 'lines': 'int',
'pointx': 'float', 'pointy': 'float', 'records': 'int'
}
}
num_years = (max_occurred - min_occurred).days / (52 * 7)
year_ranges = [
(max_occurred - relativedelta(years=offset),
max_occurred - relativedelta(years=(offset + 1)),
't{}records'.format(offset))
for offset in range(num_years)
]
for year_range in year_ranges:
_, _, records_label = year_range
schema['properties'][records_label] = 'int'
segments_with_data = []
for idx, segment in enumerate(combined_segments):
is_intersection = 'MultiLineString' == segment.type
records = segments_with_records.get(idx)
data = {
'id': idx, 'length': segment.length,
'lines': len(segment) if is_intersection else 1,
'pointx': segment.centroid.x, 'pointy': segment.centroid.y,
'records': len(records) if records else 0
}
for year_range in year_ranges:
max_occurred, min_occurred, records_label = year_range
if records:
records_in_range = [
record for record in records
if min_occurred < record['occurred'] <= max_occurred
]
data[records_label] = len(records_in_range)
else:
data[records_label] = 0
segments_with_data.append((segment, data))
9. Write out Shapefile and csv with aggregated data
The schema in the previous step is now used for writing out the Shapefile and CSV. The Shapefile is written using Fiona (passing it the schema), and the CSV is written using a DictWriter (using the schema to generate header columns).
with fiona.open(segments_shp_path, 'w', driver='ESRI Shapefile',
schema=schema, crs=road_projection) as output:
for segment_with_data in segments_with_data:
segment, data = segment_with_data
output.write({
'geometry': mapping(segment),
'properties': data
})
field_names = sorted(schema['properties'].keys())
with open(segments_csv_path, 'w') as csv_file:
csv_writer = csv.DictWriter(csv_file, fieldnames=field_names)
csv_writer.writeheader()
for segment_with_data in segments_with_data:
_, data = segment_with_data
if data['records'] > 0:
csv_writer.writerow(data)
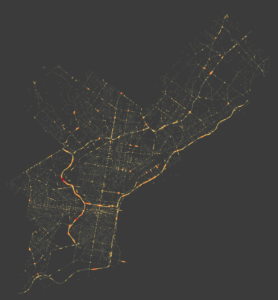 Shapefile output categorized by total crashes per segment
Shapefile output categorized by total crashes per segment
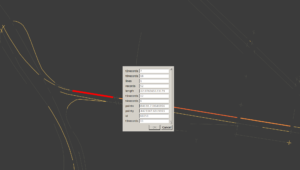 Attributes for non-intersecting segment
Attributes for non-intersecting segment
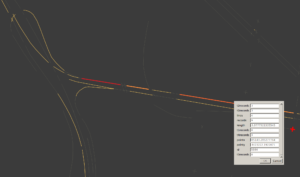 Attributes for intersection
Attributes for intersection
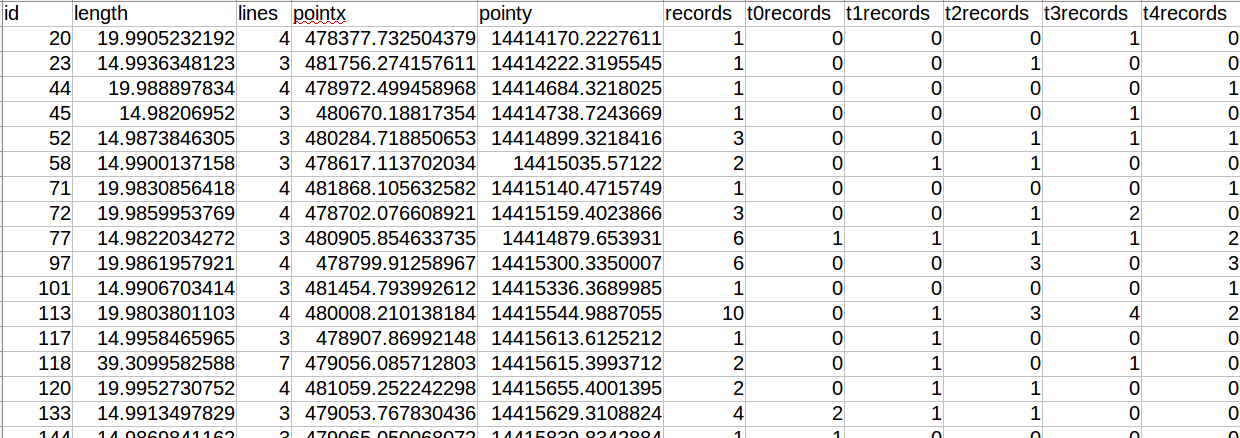 CSV output
CSV output
Optimizing intersection calculation
The major bottleneck of all the code discussed here is the calculation of intersections. Each road is compared to every other road in the network, so the number of operations grows exponentially with the number of roads. Since there are 130,000 roads in Philadelphia, this results in over 8 billion intersection checks. And in a larger region, such as the Philippines, the number of intersection checks becomes far greater.
The naive approach of checking every road against every other one is very inefficient and can be vastly improved upon by making the intersection checks more localized. For example, there’s no need to check for the intersection between two roads that are very far apart from one another. One approach for improving this is to divide the area up into a grid of tiles and perform the intersection function on each tile separately. Then the intersection checks become localized and the number of operations is dramatically cut down.
Additionally, having intersection operations confined to a tile lends itself well to multiprocessing — each tile can be processed in parallel.

Grid of tiles
The following code creates a tile iterator by finding the number of X and Y divisions by using the configured maximum tile units. A spatial index of roads is constructed to be able to quickly determine which roads are in each tile. Then the roads index is intersected with each tile boundary to collect the set of roads in each tile, and a tiles-worth of roads is yielded.
def roads_per_tile_iter():
min_x, min_y, max_x, max_y = road_bounds
bounds_width = max_x - min_x
bounds_height = max_y - min_y
x_divisions = ceil(bounds_width / tile_max_units)
y_divisions = ceil(bounds_height / tile_max_units)
tile_width = bounds_width / x_divisions
tile_height = bounds_height / y_divisions
roads_index = rtree.index.Index()
for idx, road in enumerate(roads):
roads_index.insert(idx, road.bounds)
for x_offset in range(0, int(x_divisions)):
for y_offset in range(0, int(y_divisions)):
road_ids_in_tile = roads_index.intersection([
min_x + x_offset * tile_width,
min_y + y_offset * tile_height,
min_x + (1 + x_offset) * tile_width,
min_y + (1 + y_offset) * tile_height
])
roads_in_tile = [roads[road_id] for road_id in road_ids_in_tile]
if len(roads_in_tile) > 1:
yield roads_in_tile
Multiprocessing is then used to process the tiles in parallel. First a multiprocessing pool of workers equal to the amount of cores is created. Then the intersection calculation is run on each set of roads until the iterator is exhausted. Once all work is complete, the list of multipoints is flattened into a list of single points, and the buffers are unioned to remove overlaps.
pool = multiprocessing.Pool(multiprocessing.cpu_count())
tile_intersections = pool.imap(get_intersections, roads_per_tile_iter())
pool.close()
pool.join()
buffered_intersections = [intersection.buffer(intersection_buffer_units)
for intersection in itertools.chain.from_iterable(tile_intersections)]
intersections = unary_union(buffered_intersections)
Optimizing the number of roads to consider
Many roads do not have recorded crashes, and can therefore be discarded early on in the process, which saves a great amount of processing time. The code above for reading in the road network can be modified as follows to drop any roads that do not have associated crashes.
def should_keep_road(road, road_shp, record_buffers_index):
if not len(list(record_buffers_index.intersection(road_shp.bounds))):
return False
if ('highway' in road['properties']
and road['properties']['highway'] is not None
and road['properties']['highway'] != 'path'
and road['properties']['highway'] != 'footway'):
return True
if ('class' not in road['properties'] or road['properties']['class'] == 'highway'
and road['properties']['bridge'] == 0
and road['properties']['tunnel'] == 0):
return True
return False
Resources
- The code discussed in this post has been placed into a single script version which can be found here:
https://github.com/kshepard/high-risk-traffic - The production code for the Philippines, with some additional features such as consideration of weather and fatalities can be found here:
https://github.com/WorldBank-Transport/DRIVER